Optymalizacja procedury wyszukiwania sekwencyjnego za pomocą programowania dynamicznego
Voronezh Research Institute of Communications
Otrzymano 17 maja 2001 r
Procedury wyszukiwania sekwencyjnego i dychotomicznego zostały zoptymalizowane przy użyciu metody programowania dynamicznego w celu uzyskania ich potencjalnych właściwości. Wykazano, że największy efekt uzyskuje się poprzez optymalizację dychotomii. Przeprowadzono analizę porównawczą dwóch algorytmów wyszukiwania w odniesieniu do poszukiwania sygnału w zakresie częstotliwości, podczas którego wykazano, że począwszy od pewnego bardzo niskiego stosunku sygnału do szumu, dychotomia ma zysk.
Wprowadzenie
Większość nowoczesnych systemów radiotechnicznych (RTS) obejmuje procedurę szacowania parametrów sygnału. Przykładem jest określenie częstotliwości sygnału w systemach z pseudolosowym strojeniem częstotliwości roboczej (przeskok częstotliwości), określenie opóźnienia sygnału odbitego w systemach radarowych i nawigacji, synchronizacja w cyfrowych systemach komunikacyjnych itp.
Jedną z metod szacowania parametrów jest wyszukiwanie. Podczas wyszukiwania wykonywany jest widok krok po kroku obszaru niepewności przy użyciu urządzenia jednokanałowego (lub urządzenia o dopuszczalnej liczbie kanałów). Kanał oceny w tym przypadku jest kalkulatorem funkcji wiarygodności i urządzeniem decyzyjnym dla obliczonej wartości. Jednocześnie, na każdym etapie, niepewność szacowanego parametru jest zmniejszona. Istnieją dwie różne strategie lub typy wyszukiwania - sekwencyjne i polichotomiczne. Wszystkie inne algorytmy, w ten czy inny sposób, są kombinacją tych dwóch.
W wyszukiwaniu sekwencyjnym obszar niepewności jest podzielony na komórki, których wartość jest określona przez wymagania dotyczące dokładności określania parametru żądanego sygnału (obiektu). Następnie wykonywane jest sekwencyjne testowanie hipotez dotyczących obecności obiektu wyszukiwania w jednej z komórek obszaru niepewności. Po zakończeniu testowania hipotezy podejmowana jest decyzja dotycząca dwóch alternatyw: wartość parametru odpowiada testowanej hipotezie lub nie, aw drugim przypadku następuje przejście do następnej hipotezy itd. Testowanie prostej hipotezy nazywa się krokiem wyszukiwania. Z uwagi na fakt, że decyzja na każdym kroku jest podejmowana w odniesieniu do dokładnie dwóch alternatyw, wyszukiwanie nazwano binarnym [ 1 ].
Algorytm polichotomiczny to równoległe oglądanie kilku części domeny niepewności, po których następuje decyzja o obecności obiektu wyszukiwania w jednym z nich. Następnym krokiem jest podział części domeny niepewności zdefiniowanej w poprzednim kroku itd. Wyszukiwanie jest wykonywane, dopóki partycja nie doprowadzi do wymaganej dokładności żądanego parametru. Innymi słowy, od wyszukiwania krok po kroku zawężane jest pole niepewności. Szczególnym i najprostszym przypadkiem polichotomii jest dychotomiczna procedura wyszukiwania, w której region jest podzielony na dwie części. Dychotomiczny algorytm wyszukiwania dotyczy również procedur wyszukiwania binarnego.
Obie opisane procedury wyszukiwania mogą być jednokrotne lub cykliczne. Procedury wyszukiwania jednoprzebiegowego umożliwiają przeprowadzanie wyszukiwania bez powtarzających się cykli skanowania obszaru niepewności, podczas gdy cykliczne umożliwiają powrót do poprzednich kroków wyszukiwania. Procedury jednoprzebiegowe charakteryzują się dwoma parametrami: prawdopodobieństwem pomyślnego zakończenia Q i średnim czasem wyszukiwania Tcp. W [ 2 ] pokazano, że problemy maksymalizacji prawdopodobieństwa Q dla ustalonego czasu Tcp i minimalizacji Tcp dla ustalonego Q mają wspólne rozwiązanie, tj. oba zadania prowadzą do tego samego optymalnego zestawu czasów analizy na każdym etapie wyszukiwania 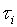 i progi detekcji Vi (w przypadku wyszukiwania z dwustopniowym solverem Wald, progi V 0 i V 1 i). Aby rozwiązać problem maksymalizacji prawdopodobieństwa sukcesu Q ze stałym średnim czasem, stosujemy metodę programowania dynamicznego.
i progi detekcji Vi (w przypadku wyszukiwania z dwustopniowym solverem Wald, progi V 0 i V 1 i). Aby rozwiązać problem maksymalizacji prawdopodobieństwa sukcesu Q ze stałym średnim czasem, stosujemy metodę programowania dynamicznego.
Głównym celem tej pracy jest badanie podejścia do optymalizacji wyszukiwania sekwencyjnego i dychotomicznego metodą programowania dynamicznego. Celem optymalizacji jest znalezienie potencjalnych cech tych procedur i ich analiza porównawcza. Optymalizacja została przeprowadzona na przykładzie wyszukiwania sygnału o stałej obwiedni (sygnał FM lub FM) z szerokością widma Df0 w zakresie częstotliwości ADF0, przy założeniu, że wyszukiwanie jest wykonywane przy użyciu detektora jednoprogowego bez pamięci, tj. Sygnał wejściowy nie może zostać nagrany i wymagana jest nowa implementacja dla każdego nowego kroku wyszukiwania.
1. Optymalizuj wyszukiwanie sekwencyjne
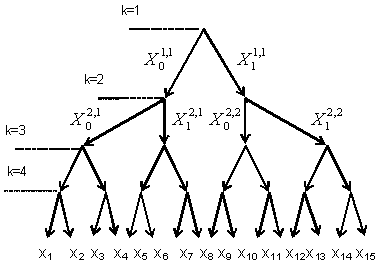
Bezpośrednie wykorzystanie metody programowania dynamicznego wymaga jednoczesnej optymalizacji czasu analizy komórki obszaru niepewności i progu wykrywania. Wyobraź sobie sekwencyjną procedurę wyszukiwania w postaci wykresu drzewa, którego wierzchołek jest węzłem odpowiadającym pierwszemu wymiarowi (patrz rysunek 1).

Rys. 1. Drzewo przeszukiwania sekwencyjnego jednoprzebiegowego.
Prawdopodobieństwo pomyślnego zakończenia wyszukiwania z węzła A-1 jest równe
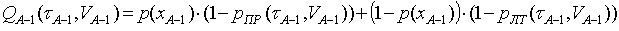 , (1)
, (1)
gdzie - czas analizy i-tej komórki obszaru niepewności, Vi - próg wykrywania, 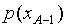 - prawdopodobieństwo a posteriori obecności sygnału w obszarze niepewności komórki A-1. Jeśli założymy, że sygnał może być równie prawdopodobny w jakiejkolwiek komórce i nie było przeskoku sygnału w poprzednich krokach i-1, to prawdopodobieństwo obecności sygnału podczas analizy i-tej komórki wynosi
- prawdopodobieństwo a posteriori obecności sygnału w obszarze niepewności komórki A-1. Jeśli założymy, że sygnał może być równie prawdopodobny w jakiejkolwiek komórce i nie było przeskoku sygnału w poprzednich krokach i-1, to prawdopodobieństwo obecności sygnału podczas analizy i-tej komórki wynosi
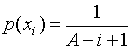 . (2)
. (2)
Ta wartość jest górną granicą prawdopodobieństwa p (xi) podczas wyszukiwania. Dolna granica wynosi zero - przypadek sygnału pomija poprzednie kroki.
W ogólnym przypadku prawdopodobieństwo udanego wyszukiwania z i-tego węzła wynosi
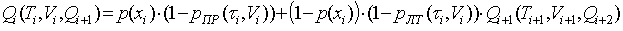 , (3)
, (3)
gdzie Ti jest czasem przeznaczonym na wyszukiwanie z i-tego węzła. Czasy ti, ti +1 i ti są powiązane następującym wyrażeniem
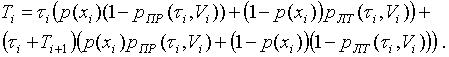 (4)
(4)
Optymalizacja programowania dynamicznego polega na tym, że dla każdego węzła drzewa wyszukiwania, począwszy od ostatniego, obliczane jest prawdopodobieństwo pomyślnego zakończenia wyszukiwania dla możliwych par wartości 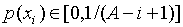 i
i 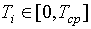 a obliczenia są następujące
a obliczenia są następujące
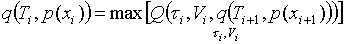 . (5)
. (5)
Prawdopodobieństwa obecności sygnału w bieżących i poprzednich krokach wyszukiwania są powiązane przez wyrażenie
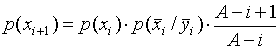 , (6)
, (6)
gdzie 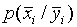 - prawdopodobieństwo, że gdy zostanie podjęta decyzja „nie ma sygnału”, to naprawdę nie jest równa
- prawdopodobieństwo, że gdy zostanie podjęta decyzja „nie ma sygnału”, to naprawdę nie jest równa
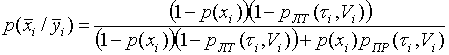 . (7)
. (7)
W teorii programowania dynamicznego [ 3 ] wyrażenie ( 5 ) nazywa się funkcją Bellmana. Zatem funkcja Bellmana obliczana dla pierwszego węzła argumentów T1 = T CP i ![W teorii programowania dynamicznego [ 3 ] wyrażenie ( 5 ) nazywa się funkcją Bellmana](/wp-content/uploads/2019/12/pl-optymalizacja-procedury-wyszukiwania-sekwencyjnego-za-pomoca-programowania-dynamicznego-14.gif) , istnieje maksymalne osiągalne prawdopodobieństwo udanego wyszukiwania dla danego czasu wyszukiwania T CP. Wielokrotne przejście przez drzewo wyszukiwania, ale od pierwszego węzła do ostatniego, pozwala przywrócić wartości progów czasów analizy i Vi, co doprowadziło do znalezionego prawdopodobieństwa sukcesu.
, istnieje maksymalne osiągalne prawdopodobieństwo udanego wyszukiwania dla danego czasu wyszukiwania T CP. Wielokrotne przejście przez drzewo wyszukiwania, ale od pierwszego węzła do ostatniego, pozwala przywrócić wartości progów czasów analizy i Vi, co doprowadziło do znalezionego prawdopodobieństwa sukcesu.
Rozważana metoda to optymalizacja dwuwymiarowa i jest bardzo pracochłonna. Znacznie bardziej akceptowalną opcją jest optymalizacja jednowymiarowa, gdy na początku są podane pewne wartości np. naprawione 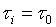 , a następnie zoptymalizuj progi wykrywania Vi w taki sposób, aby zmaksymalizować prawdopodobieństwo sukcesu. Średni czas wyszukiwania w tym przypadku można obliczyć za pomocą następującego wyrażenia
, a następnie zoptymalizuj progi wykrywania Vi w taki sposób, aby zmaksymalizować prawdopodobieństwo sukcesu. Średni czas wyszukiwania w tym przypadku można obliczyć za pomocą następującego wyrażenia
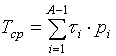 , (8)
, (8)
gdzie p i jest prawdopodobieństwem, że wyszukiwanie osiągnie i-ty krok wyszukiwania, uzyskane w sposób powtarzalny, począwszy od kroku numer jeden.
Rozważmy przypadek, gdy czas analizy we wszystkich etapach wyszukiwania jest taki sam, tj. . Rysunek 2 przedstawia zależności średniego czasu wyszukiwania sekwencyjnego zoptymalizowanego metodą dynamicznego programowania od stosunku sygnału do szumu dla A = 32-128 i prawdopodobieństw sukcesu Q = 0,9. Zakłada się, że pożądany sygnał ma stałą obwiednię, a czas wyszukiwania jest reprezentowany w odniesieniu do przedziału czasu T 0 = 1 / D f 0. Ta sama figura pokazuje zależność średniego czasu wyszukiwania w przypadku, gdy podczas sprawdzania kanałów częstotliwości ustalono próg i czas analizy.
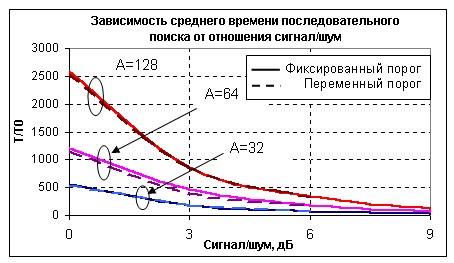
Rys. 2 Sekwencyjne porównanie wyszukiwania
procedury o stałym i zmiennym progu
Średni czas wyszukiwania jest zawsze niższy przy ustawionym progu, a prawdopodobieństwo pomyślnego przeszukiwania Q jest zawsze nieco lepsze, ale zysk nie jest znaczący.
Rozważano również przypadek, gdy czas analizy liniowo wzrasta, tj. istnieje liniowa zależność czasu analizy od liczby sprawdzanej komórki częstotliwości. W tym przypadku nachylenie linii prostej zostało dodane do zoptymalizowanych parametrów. 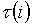 . Jednak tutaj zysk wynosi kilka procent.
. Jednak tutaj zysk wynosi kilka procent.
W rezultacie można powiedzieć, że metoda programowania dynamicznego, prowadząca do zmiennych progów wyszukiwania krok po kroku detekcji Vi i czasu akumulacji , nieznacznie wygrywa metodę optymalizacji, która zakłada, że te parametry są stałe. Jednocześnie złożoność optymalizacji przy tym drugim podejściu jest mniejsza.
2. Optymalizacja wyszukiwania dychotomicznego
Rys. 3. Drzewo wyszukiwania dychotomicznego
Pojedyncze dychotomiczne poszukiwanie sygnału wąskopasmowego w zakresie częstotliwości obejmuje wykonanie kroków N = log 2 A, gdzie w pierwszym etapie cały analizowany zakres częstotliwości jest podzielony na dwie części i określa się, w której połowie znajduje się żądany sygnał. W drugim kroku podzakres znaleziony w poprzednim kroku itd. Jest dzielony na pół. W rezultacie w ostatnim kroku dokonuje się wyboru pomiędzy podpasmami zawierającymi jedną komórkę na raz. Ostateczne prawdopodobieństwo pomyślnego przeszukania Q w tym przypadku będzie równe iloczynowi prawdopodobieństwa podjęcia właściwej decyzji na każdym etapie Qi, gdzie i = 1, N. Jeśli określony czas Tcp jest określony, podczas którego konieczne jest przeprowadzenie wyszukiwania, wówczas jedną z opcji dystrybucji dostępnego całkowitego czasu między krokami jest taka, w której prawdopodobieństwa podjęcia prawidłowej decyzji na każdym kroku są równe, tj. 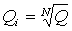 . Nazwijmy to najpierw.
. Nazwijmy to najpierw.
Jednak od kroku do kroku, szerokość analizowanego podzakresu częstotliwości zmienia się, a zatem stosunek sygnału do szumu zmienia się na wejściu decydującego urządzenia, decydując na korzyść jednego lub drugiego podpasma. Uzasadnione jest zatem założenie, że wybór prawdopodobieństw nieoptymalny. Zoptymalizujmy rozkład czasu dychotomicznego poszukiwania sygnału między krokami metodą programowania dynamicznego i nazwijmy to podejście drugim.
Załóżmy, że pożądany sygnał ma stałą obwiednię i czas analizy w kroku wyszukiwania T >> 1 / D f 0, a wyszukiwanie jest wykonywane przy użyciu dwóch filtrów z przestrajalnym pasmem i częstotliwością centralną. Oblicza się różnicę między sygnałami wyjściowymi filtrów, wykrywaniem i niekoherentną akumulacją. Decyzja na korzyść jednego lub drugiego podzakresu jest podejmowana za pomocą przelicznika (RF) porównującego uzyskaną wartość z progiem zerowym. W takim przypadku prawdopodobieństwo podjęcia właściwej decyzji przy użyciu pojedynczego progu RP w i-tym kroku wyszukiwania jest równe
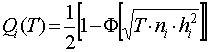 , (9)
, (9)
gdzie 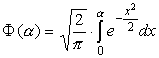 - Funkcja Crump;
- Funkcja Crump; 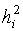 - stosunek sygnału do szumu na wejściu rozdzielnicy w i-tym kroku wyszukiwania przy braku akumulacji, w zależności od liczby kroków wyszukiwania i stosunku sygnału do szumu w komórce elementarnej
- stosunek sygnału do szumu na wejściu rozdzielnicy w i-tym kroku wyszukiwania przy braku akumulacji, w zależności od liczby kroków wyszukiwania i stosunku sygnału do szumu w komórce elementarnej 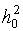 ;
; 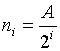 - liczba zgromadzonych próbek w przedziale czasowym 1 / D f 0, w zależności od liczby etapów wyszukiwania dychotomicznego; T - czas analizy na etapie wyszukiwania, przedstawiony względem przedziału 1 / D f 0. Należy zauważyć, że w zależności od numeru kroku wyszukiwania może istnieć inna liczba zgromadzonych próbek n w przedziale czasu 1 / D0, ponieważ podpasma częstotliwości o różnej szerokości są analizowane w różnych etapach.
- liczba zgromadzonych próbek w przedziale czasowym 1 / D f 0, w zależności od liczby etapów wyszukiwania dychotomicznego; T - czas analizy na etapie wyszukiwania, przedstawiony względem przedziału 1 / D f 0. Należy zauważyć, że w zależności od numeru kroku wyszukiwania może istnieć inna liczba zgromadzonych próbek n w przedziale czasu 1 / D0, ponieważ podpasma częstotliwości o różnej szerokości są analizowane w różnych etapach.
Jeśli przy wyszukiwaniu z węzła na ostatnim poziomie przydzielono czas t, a poprzednie kroki były wolne od błędów, to prawdopodobieństwo prawidłowego zakończenia wyszukiwania 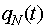 równa się
równa się
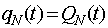 . (10)
. (10)
To samo prawdopodobieństwo dla przedostatniego poziomu jest
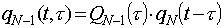 , (11)
, (11)
gdzie 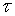 - czas przydzielony do (N -1) -tego kroku i
- czas przydzielony do (N -1) -tego kroku i 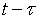 - następny.
- następny.
W ogólnym przypadku mamy i-ty krok
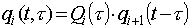 . (12)
. (12)
Optymalizacja programowania dynamicznego polega na tym, że dla każdego poziomu drzewa wyszukiwania, począwszy od ostatniego, obliczane jest prawdopodobieństwo pomyślnego zakończenia wyszukiwania 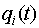 dla wszystkich możliwych wartości
dla wszystkich możliwych wartości 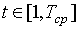 a obliczenia są następujące
a obliczenia są następujące
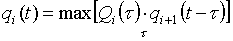 . (13)
. (13)
Wyrażenie ( 13 ) jest funkcją Bellmana, a jej wartość obliczona dla pierwszego kroku argumentu Tcp, jest maksymalnym możliwym do osiągnięcia prawdopodobieństwem sukcesu dla danego czasu wyszukiwania Tcp. Wielokrotne przejście przez drzewo wyszukiwania, ale od pierwszego poziomu do ostatniego, pozwala przywrócić wartości czasów analizy Ti, co doprowadziło do znalezionego prawdopodobieństwa sukcesu. Na podstawie znanego Ti można określić prawdopodobieństwa poprawnego rozwiązania na każdym etapie wyszukiwania Qi.
On Rys. 4 pokazuje zależność czasu wyszukiwania sygnału w zakresie częstotliwości od 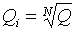 (pierwsze podejście) i wyszukiwanie zoptymalizowane przez programowanie dynamiczne (drugie podejście).
(pierwsze podejście) i wyszukiwanie zoptymalizowane przez programowanie dynamiczne (drugie podejście).
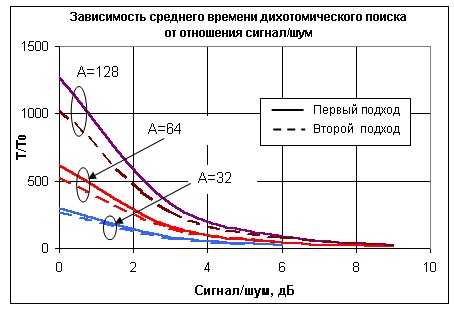
Rys. 4 Porównanie dwóch podejść do budowania wyszukiwania dychotomicznego
Jak wynika z rysunku, metoda programowania dynamicznego pozwala lepiej rozłożyć całkowity czas wyszukiwania między etapami. Rozkład czasu prowadzi do tego, że w pierwszych krokach prawdopodobieństwo prawidłowej decyzji jest mniejsze niż w drugim. W rezultacie zyskuje się przed pierwszym podejściem, a wzmocnienie wzrasta wraz ze wzrostem wartości zakresu częstotliwości A i ze spadkiem stosunku sygnału do szumu.
3. Porównanie algorytmów wyszukiwania sekwencyjnego i dychotomicznego
Uzyskane powyżej charakterystyki algorytmów wyszukiwania sekwencyjnego i dychotomicznego są potencjalne, a zatem ich analiza porównawcza jest interesująca.
Najpierw definiujemy górne i dolne granice stosunku średnich czasów wyszukiwania. Przy dużym stosunku sygnału do szumu wymagana jest jedna próbka do podjęcia decyzji w kroku wyszukiwania, niezależnie od algorytmu wyszukiwania. W przypadku wyszukiwania sekwencyjnego maksymalna liczba kroków jest równa A-1, a przy równomiernym znalezieniu sygnału w zakresie częstotliwości średnia liczba kroków jest równa (A-1) / 2, a minimalny średni czas wyszukiwania jest równy
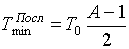 . (14)
. (14)
Z dychotomią średni czas jest
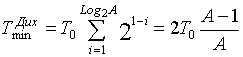 . (15)
. (15)
W wyniku podziału ( 14 ) na ( 15 ) okazuje się, że R = A / 4 . Zatem dychotomia zysku marginalnego jest proporcjonalna do wielkości regionu niepewności A.
Analiza zachowania krzywej rys.2 i rys.4 w rejonie niskiego stosunku sygnału do szumu h 0 2 , prezentowany w skali logarytmicznej, daje podstawy do zbliżenia ich do następujących funkcji:
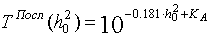 , (16)
, (16)
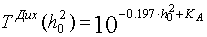 , (17)
, (17)
gdzie stosunek sygnału do szumu h02 jest wyrażony w decybelach, a KA jest współczynnikiem określonym przez wielkość obszaru niepewności A. Zatem dla wyszukiwania sekwencyjnego z Q = 0,9 i A = 32; 64; 128 współczynnik KA = 2,678; 3,01; 3 346 odpowiednio. Dla dychotomii KA = 2,39; 2 704; 3.01. Na podstawie wyrażeń ( 16 ), ( 17 ) możesz określić wartość h02 , poniżej której wyszukiwanie sekwencyjne będzie szybsze niż dychotomiczne:
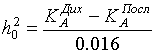 . (18)
. (18)
Dla A = 32; 64; 128 ta wartość jest równa h02 = -18; -19,1; -21 dB
On rys.5 Przedstawiono zależności stosunku średnich czasów przeszukiwania sekwencyjnego i dychotomicznego. Z rysunku wynika, że począwszy od bardzo niskiego stosunku sygnału do szumu, wygrywa wyszukiwanie dychotomiczne.
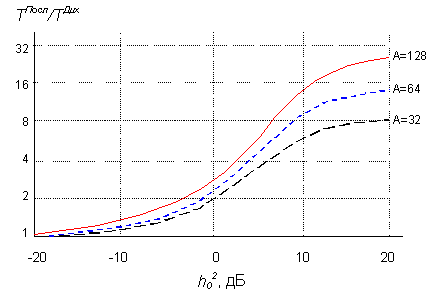
Rys. 5. Stosunek średniego czasu sekwencyjnego i dychotomicznego wyszukiwania
Wniosek
W trakcie pracy dostosowano metodę programowania dynamicznego do optymalizacji sekwencyjnych i dychotomicznych algorytmów wyszukiwania w celu znalezienia ich potencjalnych cech. Klasyfikacja parametrów algorytmów wyszukiwania, w wyniku której liczba parametrów do optymalizacji była ograniczona, co doprowadziło do znacznego uproszczenia optymalizacji. Wykazano, że najbardziej efektywne czasowo wyszukiwanie dynamiczne pozwala na optymalizację dychotomii.
Porównanie potencjalnych cech sekwencyjnego wyszukiwania i dychotomii w odniesieniu do poszukiwania sygnału w zakresie częstotliwości wykazało, że począwszy od pewnego bardzo niskiego stosunku sygnału do szumu, dychotomia wygrywa o średni czas wyszukiwania.
Literatura
1. Kanevsky Z.M., Litwinienko V.P. Teoria skradania się. - Woroneż: wydawnictwo VGU, 1991. - 144s.
2. Vasilenko O.O. Streszczenie pracy „Optymalizacja poszukiwania sygnałów komunikacyjnych i kontrola w problemach analizy stealth”. Voronezh, VSTU 1999.
3. Bellman, R. Procesy regulacji adaptacji. M., 1964.
Autor:
Anatolij G. Filatov, e-mail: filatov @kodofon .vrn .ru ,
Voronezh Research Institute of Communications