Аптымізацыя праграмнага кода для ЦСП TMS320C6000
У чацвёртай артыкуле цыклу разглядаюцца спосабы аптымізацыі праграмнага кода на аснове канвеера і паралельнай апрацоўкі зьмяняй каманд для лічбавых сігнальных працэсараў сямейства С6000 кампаніі Texas Instruments (TI). Для засваення матэрыялу рэкамендуецца азнаёміцца з папярэднімі публікацыямі ( «Кіт» № 7-9'2005).
Аптымізацыя праграмнага кода можа быць выканана на некалькіх узроўнях:
- на ўзроўні алгарытму - аптымізуецца С-код;
- на ўзроўні архітэктуры ЦСП - аптымізуецца зьмяняй код.
У разгляданым прыкладзе аптымізацыю правядзем для функцыі скруткі convolution () з праекту, разгледжанага ў папярэдніх артыкулах цыклу.
Спачатку неабходна запусціць CCS і стварыць новы праект. Нагадаем, што для гэтага ў галоўным меню ИСР трэба абраць частку Project, у ім - пункт New, затым у якое з'явілася дыялогавым акне выбіраюцца сямейства ЦСП і тып праекта, а таксама паказваецца месца размяшчэння праекта на цвёрдым дыску і яго імя.
У тэчку праекта скапіяваць файлы з зыходным Сі-кодам разгледжанага ў мінулым артыкуле фільтра. Скапіраваныя файлы, за выключэннем загалоўкавыя файла «f ilter.h», падключаюцца да праекта (у галоўным меню - раздзел Project, а ў ім - пункт Add Files to Project). Нагадаем, што загалоўкавыя файл падключаецца аўтаматычна пры кампіляцыі праекта.
У Сі-кодзе оптимизируемой функцыі выдаляецца цыкл зруху за кошт выкарыстання цыклавой адрасавання. Мадэрнізаваны праграмны код функцыі convolution () прыме выгляд:
word16 convolution (word16 * pSimplBuff, word16 * pCoeffBuff, word16 * pSimplMin, word16 lenFir, word32 lenSimpl) {// Аб'ява зменных word32 count; // Ясна цыклу word32 summa; // Ясна для часовага // захоўвання выніку назапашвання // множання word32 coeff; // Каэфіцыент фільтра word32 simpl; // Бягучы адлік word32 mpy; // Вынік множання word16 * pSimplMax; // Максімальны адрас буфера // затрыманых адлікаў word16 flag; // Сцяг цыклічнай адрасавання // Ініцыялізацыя зменных summa = 0; pSimplMax = pSimplMin + lenSimpl - 1; // Вылічэнне скруткі for (count = lenFir - 1; count> = 0; count -) {// Чытанне адліку simpl = * pSimplBuff ++; // Чытанне каэфіцыента coeff = * pCoeffBuff ++; // Множанне каэфіцыента на адлік mpy = simpl * coeff; // Сумаванне з назапашваннем summa + = mpy; // Арганізацыя цыклічнай адрасавання if (pSimplBuff> pSimplMax) flag = 1; else flag = 0; if (flag) pSimplBuff = pSimplMin; } // Нармалізацыя выніку summa >> = 15; // Зварот з функцыі выніку скруткі return summa; }
З'явіліся дадатковыя параметры выкліку функцыі:
- pSimplMin - паказальнік на пачатак буфера затрымкі;
- lenSimpl - даўжыня лініі затрымкі.
Асаблівасць кода ў тым, што даўжыня лініі затрымкі павінна быць кратная двум байтам і быць больш даўжыні фільтра. Першае абмежаванне абумоўлена спосабам рэалізацыі цыклавой адрасавання ў сямействе ЦСП TMS320C6000. Змена інтэрфейсу функцыі цягне неабходнасць зменаў і ў іншых кампанентах праекта.
У загалоўкавыя файле «filter.h» неабходна:
- змяніць аб'яву функцыі скруткі:
extern word16 convolution (word16 *, word16 *, word16 *, word16, word32); - дапоўніць аб'яву тыпу кантэкстнай структуры параметрамі pSimplMin, і lenSimpl:
typedef struct {word16 * pInpBuff; // Паказальнік на ўваходных буфер word16 * pOutBuff; // Паказальнік на выхадны буфер word16 lenBuff; // Даўжыня ўваходнага і выходнага буфераў word16 * pSimplBuff; // Бягучы паказальнік на буфер лініі // затрымкі word16 * pSimplMin; // Паказальнік на пачатак буфера лініі // затрымкі word16 * pCoeffBuff; // Паказальнік на буфер // з каэфіцыентамі фільтра word16 lenFilter; // Даўжыня буфераў лініі затрымкі // і каэфіцыентаў word32 mCoeff; // маштабуецца каэфіцыент word32 lenSimpl; // Даўжыня лініі затрымкі} CONTEXTFILTER; - вызначыць макрас для ініцыялізацыі новага поля кантэкстнай структуры:
У функцыі initFilter () неабходна дадаць ініцыялізацыю новых палёў кантэкстнай структуры:
pCntx-> pSimplMin = simplBuff; pCntx-> lenSimpl = LENSIMPL;
а таксама змяніць верхні мяжа ў цыкле пачатковай ачысткі буфера лініі затрымкі:
for (i = 0; i pSimplBuff [i] = 0;
У файле «const.cpp» змяніць стварэнне буфера затрыманых адлікаў:
#pragma DATA_ALIGN (LENSIMPL
Дырэктыва #pragma DATA_ALIGN (LENSIMPL
Лістынг новай функцыя запуску фільтрацыі runFilter () прыведзены ніжэй.
void runFilter (CONTEXTFILTER * pCntx) {// Лакальныя зменныя word16 * pInpBuff; // Паказальнік на ўваходных буфер word16 * pOutBuff; // Паказальнік на выхадны буфер word16 lenBuff; // Даўжыня ўваходнага і выходнага буфераў word16 * pSimplBuff; // Бягучы паказальнік на буфер лініі // затрымкі word16 * pSimplMin; // Паказальнік на пачатак буфера лініі // затрымкі word16 * pSimplMax; // Паказальнік на канец буфера лініі // затрымкі word16 * pCoeffBuff; // Паказальнік на буфер // з каэфіцыентамі фільтра word16 lenFilter; // Даўжыня буфераў лініі затрымкі // і каэфіцыентаў word32 mCoeff; // маштабуецца каэфіцыент word32 count; // Ясна цыклу word32 coeff; // Дапаможная пераменная word32 lenSimpl; // Даўжыня лініі затрымкі // Ініцыялізацыя лакальных зменных pInpBuff = pCntx-> pInpBuff; pOutBuff = pCntx-> pOutBuff; lenBuff = pCntx-> lenBuff; pSimplBuff = pCntx-> pSimplBuff; pSimplMin = pCntx-> pSimplMin; pCoeffBuff = pCntx-> pCoeffBuff; lenFilter = pCntx-> lenFilter; mCoeff = pCntx-> mCoeff; lenSimpl = pCntx-> lenSimpl; pSimplMax = pSimplMin + lenSimpl - 1; // Цыкл апрацоўкі уваходнага буфера for (count = 0; count> = 15; // Запіс у буфер затрыманых адлікаў * pSimplBuff = (word16) coeff; // Вызначэнне выхаднога адліку coeff = convolution (pSimplBuff, pCoeffBuff, pSimplMin, lenFilter, lenSimpl ); // Запіс выхаднога адліку pOutBuff [count] = (word16) coeff; // Декрементация адрасу буфера затрыманых адлікаў pSimplBuff--; // Арганізацыя цыклічнай адрасавання if (pSimplBuff pSimplBuff = pSimplBuff;}
Неабходна стварыць новы зыходны файл, набраць тэкст, зьмяняй кода оптимизируемой функцыяй скруткі і захаваць файл з імем «convolution_my_2.asm». Затым падлучыць файл з зьмяняй кодам функцыі скруткі да праекту, а файл з Сі-кодам выключыць з працэсу кампіляцыі. Як гэта зрабіць, было паказана ў папярэдніх артыкулах цыклу. Зьмяняй код функцыі скруткі мае выгляд:
; Прызначэнне імёнаў рэгістраў .asg A2, flag_A; word16 flag; // Сцяг цикли- // часаннем адре- // сации .asg A3, mpy_A; word32 mpy; // Вынік // множання .asg A4, pSimplBuff_A; word16 * pSimplBuff; // Першы // параметр // функцыі .asg A5, simpl_A; word32 simpl; // Бягучы // адлік .asg A6, pSimplMin_A; word16 * pSimplMin // Трэці // параметр // функцыі .asg A7, summa_A; word32 sum; // Ясна // для накопле- // ня умно- // жений .asg A8, lenSimpl_A; word32 maskIndex; // Пяты // параметр // функцыі .asg A9, pSimplMax_A; word16 * pSimplMax; // Максималь- // ны адрас // буфера // адлікаў .asg B0, count_B; Пераменная цыклу .asg B3, adrReturn_B; Адрас вяртання .asg B4, pCoeffBuff_B; word16 * pCoeffBuff; // Другі // параметр // функцыі .asg B5, coeff_B; word32 coeff; // Коэффици- // ент фільтра .asg B6, lenFir_B; word16 lenFir; // Чацвёрты // параметр // функцыі .asg B15, SP; Паказальнік на стэк; Вызначэнне функцыі .sect «.text»; секцыя размяшчэння функцыі .global _convolution__FPsN21si; імя функцыі _convolution__FPsN21si:; кропка ўваходу ў функцыю; Забарона перапыненняў MVC .S2 CSR, B0 AND .S2 B0, -2, B1 MVC .S2 B1, CSR; Захаванне рэгістраў ў стэку STW .D2T2 B0, * -SP [11]; Алгарытм апрацоўкі; Ініцыялізацыя зменных ZERO .D1 summa_A; summa = 0; ; pSimplMax = pSimplMin + lenSimpl - 1; SUB .S1 lenSimpl_A, 1, lenSimpl_A ADDAH .D1 pSimplMin_A, lenSimpl_A, pSimplMax_A; Вылічэнне скруткі; for (count = lenFir - 1; count> = 0; count -) {; Вызначэнне пачатковага значэння зменнай цыклу SUB .L2 lenFir_B, 1, count_B loop01:; Кропка вяртання пры цыклічных вылічэннях; Чытанне адліку; simpl = * pSimplBuff ++; ; Чытанне каэфіцыента; coeff = * pCoeffBuff ++; LDH .D2T2 * pCoeffBuff_B ++, coeff_B; coeff = * pCoeffBuff ++; || LDH .D1T1 * pSimplBuff_A ++, simpl_A; simpl = * pSimplBuff ++; NOP 4; Чаканне завяршэння аперацыі чытання; дадзеных з памяці; Множанне каэфіцыента на адлік MPY .M1X coeff_B, simpl_A, mpy_A; mpy = coeff * simpl; NOP; Чаканне завяршэння аперацыі множання ADD .S1 summa_A, mpy_A, summa_A; summa + = mpy; ; Арганізацыя цыклічнай адрасавання; if (pSimplBuff> pSimplMax) flag = 1; ; else flag = 0; CMPGT .L1 pSimplBuff_A, pSimplMax_A, flag_A; if (flag) pSimplBuff = pSimplMin; [Flag_A] MV .S1 pSimplMin_A, pSimplBuff_A,; Умоўны пераход пры цыклічных вылічэннях і; адначасовая умоўная декрементация зменнай; цыклу [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B NOP 5; Чаканне завяршэння аперацыі ўмоўнага; пераходу; }; Нармаванне выніку падсумоўвання SHR .S1 summa_A, 15, summa_A; sum >> = 15; ; Аднаўленне службовых рэгістраў LDW .D2T2 * -SP [11], B0 NOP 4; Чаканне завяршэння апошняй аперацыі; чытання (4 такту); Аднаўленне рэгістра CSR MVC .S2 B0, CSR; Выхад з функцыі; Перасоўванне вяртаецца значэння ў рэгістр A4 MV .S1 summa_A, A4 B .S2 adrReturn_B NOP 5; Чаканне завяршэння аперацыі безумоўнага; пераходу (5 тактаў)
Праграмны код, прадстаўлены вышэй, не з'яўляецца аптымальным. Яго неабходна мадэрнізаваць. На першым кроку выкарыстоўваем магчымасць арганізацыі цыклавой адрасавання ў ЦСП TMS320C6000.
Для арганізацыі цыклічнай адрасавання выкарыстоўваюцца рэгістры агульнага прызначэння A4-A7 і B4-B7. Рэжым працы дадзеных Рон вызначаецца службовым рэгістрам ARM. Структура рэгістра AMR паказаная на мал. 1.

Мал. 1. Структура службовага рэгістра ARM
Рэжым працы рэгістра, абранага для цыклічнай адрасавання, вызначаецца значэннем палёў A4-A7 і B4-B7 (адпаведных Рон аналагічнага назвы):
- «00» - лінейная адрасаванне (рэжым па змаўчанні);
- «01» - цыклічная адрасаванне з указаннем даўжыні буфера ў поле BK0;
- «10» - цыклічная адрасаванне з указаннем даўжыні буфера ў поле BK1;
- «11» - рэзерв.
Даўжыня буфера цыклічнай адрасавання ў байтах вызначаецца значэннем палёў BK0 і BK1 (табл. 1).
Табліца 1. Памер буфера ў залежнасці ад значэння палёў BK0 і BK1 рэгістра ARM
Значэнне Памер значэнне Памер значэнне Памер значэнне Памер 00000 2 01000 512 10000 131 072 11000 33 554 432 00001 4 01001 1024 10001 262 144 11001 67 108 864 00010 8 01010 2048 10010 524 288 11010 67 108 864 00011 16 01011 4096 10011 1 048 576 11011 268 435 456 00100 32 01100 8192 10100 2 097 152 11100 536 870 912 00101 64 01101 16 384 10101 4 194 304 11101 1 073 741 824 00110 128 01110 32 768 10110 8 388 608 11110 2 147 483 648 00111 256 01111 65 536 10111 16 777 216 11111 4 294 967 296
Код, зьмяняй функцыі з цыклавой адрасаваннем паказаны ніжэй. Захоўваецца ён у файле «convolution_my_3.asm». Неабходна яго стварыць, падключыць да праекта і выключыць з працэсу кампіляцыі папярэдні файл «convolution_my_2.asm».
; Прызначэнне імёнаў рэгістраў .asg A3, mpy_A; word32 mpy; // Вынік // множання .asg A4, pSimplBuff_A; word16 * pSimplBuff; // Першы // параметр // функцыі .asg A5, simpl_A; word32 simpl; // Бягучы // адлік .asg A7, summa_A; word32 sum; // Ясна // для накопле- // ня умноже- // няў .asg A8, maskIndex_A; word32 maskIndex; // Пяты // параметр // функцыі .asg B0, count_B; Пераменная цыклу .asg B3, adrReturn_B; Адрас вяртання .asg B4, pCoeffBuff_B; word16 * pCoeffBuff; // Другі // параметр // функцыі .asg B5, coeff_B; word32 coeff; // Каэфіцыент // фільтра .asg B6, lenFir_B; word16 lenFir; // Чацвёрты // параметр // функцыі .asg B15, SP; Паказальнік на стэк; Вызначэнне функцыі .sect «.text»; секцыя размяшчэння функцыі .global _convolution__FPsN21si; імя функцыі _convolution__FPsN21si:; кропка ўваходу ў функцыю; Забарона перапыненняў MVC .S2 CSR, B0 AND .S2 B0, -2, B1 MVC .S2 B1, CSR; Вызначыць рэжым цыклічнай адрасавання для рэгістра A4 MVC .S2 AMR, B2 MVKL .S2 0x1, B1 MVKLH .S2 0x7, B1 MVC .S2 B1, AMR; Захаванне службовых рэгістраў ў стэку STW .D2T2 B0, * -SP [11] STW .D2T2 B2, * -SP [12]; Алгарытм апрацоўкі; Ініцыялізацыя зменных ZERO .D1 summa_A; summa = 0; ; Цыкл вылічэнні скруткі; for (count = lenFir - 1; count> = 0; count -) {; Вызначэнне пачатковага значэння зменнай цыклу SUB .L2 lenFir_B, 1, count_B loop01:; Кропка вяртання пры цыклічных вылічэннях; Чытанне адліку; simpl = * pSimplBuff ++; ; Чытанне каэфіцыента; coeff = * pCoeffBuff ++; LDH .D2T2 * pCoeffBuff_B ++, coeff_B; coeff = * pCoeffBuff ++; || LDH .D1T1 * pSimplBuff_A ++, simpl_A; simpl = * pSimplBuff ++; NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці; Умоўны пераход пры цыклічных вылічэннях і; адначасовая умоўная декрементация зменнай; цыклу [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці; Множанне каэфіцыента на адлік MPY .M1X coeff_B, simpl_A, mpy_A; mpy = coeff * simpl; NOP; Чаканне завяршэння аперацыі множання ADD .S1 summa_A, mpy_A, summa_A; summa + = mpy; ; } Канец цыклу вылічэнні скруткі; Нармаванне выніку падсумоўвання SHR .S1 summa_A, 15, summa_A; sum >> = 15; ; Аднаўленне службовых рэгістраў LDW .D2T2 * -SP [11], B0 LDW .D2T2 * -SP [12], B2 NOP 4; Чаканне завяршэння апошняй аперацыі; чытання (4 такту); Аднаўленне рэгістраў MVC .S2 B0, CSR MVC .S2 B2, AMR; Выхад з функцыі; Перасоўванне вяртаецца значэння ў рэгістр A4 MV .S1 summa_A, A4 B .S2 adrReturn_B NOP 5; Чаканне завяршэння аперацыі; безумоўнага пераходу (5 тактаў)
Затым неабходна правесці кампіляцыю праекта, загрузіць атрыманы бінарны файл у ЦСП, запусціць на выкананне праграму і пераканацца ў правільнасці выніку. Як гэта зрабіць, было падрабязна разгледжана ў папярэдніх артыкулах цыклу.
Асаблівасці прыведзенага кода:
- каманда чакання завяршэння загрузкі дадзеных з памяці «NOP 4» заменена чатырма паслядоўнымі камандамі «NOP» для зручнасці далейшай аптымізацыі;
- каманда ўмоўнага пераходу «[count_B] B .S2 loop01» перанесена на 5 тактаў ўверх, што дазваляе адмовіцца ад каманды чакання завяршэння ўмоўнага пераходу «NOP 5» у канцы цыклу.
Далейшая аптымізацыя заключаецца ў арганізацыі паралельных вылічэнняў і канвеернай апрацоўкі каманд. Сутнасць канвеера ў тым, што чарговая каманда пачынае выконвацца да завяршэння папярэдняй. Гэта магчыма з-за таго, што кожная каманда выконваецца за некалькі тактаў: чытанне каманды (ЧК), дэшыфраванне каманды (ДК), чытанне аперанд каманды (ЧА1, ЧА2 і т. Д.), Выкананне каманды (ВК) і захаванне выніку (СР ). Градацыя досыць умоўная, але дазваляе праілюстраваць ідэю канвеера. На мал. 2a паказана праца ЦСП без канвеера, а на мал. 2б - з канвеерам. Такім чынам, выкананне каманд (пасля пэўнай затрымкі) адбываецца за адзін такт.
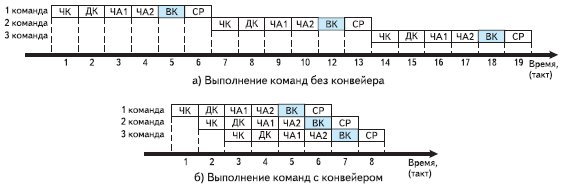
Мал. 2. Выкананне каманд з канвеерам і без яго
Для ЦСП TMS320C6000 існуе два тыпу канвеераў - праграмны і апаратны. Апаратны канвеер «празрысты» для праграмавання і дазваляе лічыць, што большасць каманд выконваецца за адзін такт (мае нулявую затрымку). А вось праграмны канвеер з'яўляецца магутным інструментам аптымізацыі кода.
Рэалізацыя праграмнага канвеера для функцыі скруткі паказаная на прыкладзе блока «Цыкл вылічэнні скруткі» у яе зьмяняй кодзе. Прыкладны працэдура арганізацыі канвеера заключаецца ў наступным:
- Вынесці з цыклу некалькі ітэрацый цыклічных вылічэнняў і выканаць іх паслядоўна. Колькасць выносяцца ітэрацый роўна колькасці тактаў (уключаючы пустыя аперацыі) у адным кроку цыклу. Пры гэтым з вынесеных ітэрацый выключаецца каманда ўмоўнага пераходу. Частка праграмнага кода, адпаведнага дадзе- ному этапу, мае выгляд:
; Цыкл вылічэнні скруткі; for (count = lenFir - 1; count> = 0; count -) {; Вызначэнне пачатковага значэння зменнай цыклу SUB .L2 lenFir_B, 1, count_B; 1-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A NOP [count_B] SUB .L2 count_B, 1, count_B NOP NOP MPY .M1X coeff_B, simpl_A, mpy_A NOP ADD .S1 summa_A, mpy_A, summa_A; 2-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A NOP [count_B] SUB .L2 count_B, 1, count_B NOP NOP MPY .M1X coeff_B, simpl_A, mpy_A NOP ADD .S1 summa_A, mpy_A, summa_A; 3я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; 4-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; 5-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; 6-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; 7-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; 8-я ітэрацыя цыкла ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ; Тыя, што засталіся ітэрацыі цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;; loop01:; Кропка вяртання пры цыклічных вылічэннях; Чытанне адліку simpl = * pSimplBuff ++; ; Чытанне каэфіцыента coeff = * pCoeffBuff ++; LDH .D2T2 * pCoeffBuff_B ++, coeff_B; coeff = * pCoeffBuff ++; || LDH .D1T1 * pSimplBuff_A ++, simpl_A; simpl = * pSimplBuff ++; NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці; Множанне каэфіцыента на адлік MPY .M1X coeff_B, simpl_A, mpy_A; mpy = coeff * simpl; NOP; Чаканне завяршэння аперацыі; множання ADD .S1 summa_A, mpy_A, summa_A; summa + = mpy; ; } Канец цыклу вылічэнні скруткі
Рэкамендуецца ў навучальных мэтах стварыць новы зьмяняй файл (напрыклад, з імем «convolution_my_4.asm») і захаваць у ім зменены код функцыі скруткі.
- Вызначыць магчымасць арганізацыі паралельных вылічэнняў. Гэта залежыць ад колькасці аперацый і іх тыпу. За адзін такт можна выканаць 8 аперацый. Дзве з іх павінны быць множання. Не больш за два аперацый чытання-запісу памяці. Дзве аперацыі неабходныя для арганізацыі цыклічных вылічэнняў. Варта прааналізаваць, якія модулі АЛУ задзейнічаны і ці няма скрыжаванняў - тут важным з'яўляецца размеркаванне зменных па баках A і B рэгістраў агульнага прызначэння. Акрамя гэтага, неабходна высветліць, ці няма канфлікту ў выкарыстанні шляхоў камутацыі і кроссировки. Пустыя аперацыі (NOP) не ўлічваюцца. У выніку вызначаецца колькасць блокаў з паралельным выкананнем каманд, неабходных для выканання ўсіх дзеянняў на адным кроку цыклу. Фарміраваць блокі з аперацый цыкла неабходна без уліку таго, што вынік адной аперацыі можа быць зыходным значэннем для іншай.
У разгляданым прыкладзе можна выканаць усе аперацыі ў адным блоку (паралельна): дзве аперацыі чытання дадзеных з памяці (шляхі камутацыі не перасякаюцца), аперацыя ўмоўнага пераходу, аперацыя декрементации зменнай цыклу, адно множанне і адно сумаванне (модулі не перасякаюцца, выкарыстоўваецца толькі адзін крос -путь).
- Вырабіць «злепванне» першых васьмі (для дадзенага прыкладу) ітэрацый цыклу. З улікам таго, што ўсе аперацыі ў адным цыкле могуць быць выкананы ў адным блоку паралельных каманд, «злепванне» вырабляецца са зрушэннем на адзін крок. Як гэта зрабіць, паказана ў табліцы 2.
Табліца 2. Прыклад «склейвання» першых трох ітэрацый
1 ітэрацыя 2 ітэрацыя 3 ітэрацыя Вынік "склейвання" LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A NOP LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B NOP LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B
|| LDH .D2T2 * pCoeffBuff_B ++, coeff_B
|| LDH .D1T1 * pSimplBuff_A ++, simpl_A NOP [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B NOP [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B NOP NOP [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B [count_B] B .S2 loop01
|| [Count_B] SUB .L2 count_B, 1, count_B MPY .M1X coeff_B, simpl_A, mpy_A NOP NOP MPY .M1X coeff_B, simpl_A, mpy_A NOP MPY .M1X coeff_B, simpl_A, mpy_A NOP MPY .M1X coeff_B, simpl_A, mpy_A ADD .S1 summa_A, mpy_A, summa_A NOP MPY .M1X coeff_B, simpl_A, mpy_A ADD .S1 summa_A, mpy_A, summa_A
|| MPY .M1X coeff_B, simpl_A, mpy_A ADD .S1 summa_A, mpy_A, summa_A NOP ADD .S1 summa_A, mpy_A, summa_A ADD .S1 summa_A, mpy_A, summa_A ADD .S1 summa_A, mpy_A, summa_A
Першыя 8 «злепленых» крокаў цыклу ўяўляюць сабой праграмны канвеер вылічэнняў: чытанне з памяці новых дадзеных пачынаецца да заканчэння апрацоўкі ўжо прачытаных. У працэсе загрузкі бягучых дадзеных (якая выконваецца з затрымкай на 4 такту) вырабляецца апрацоўка папярэдніх. Да моманту з'яўлення дадзеных у прыёмных рэгістрах для бягучага каэфіцыента фільтра і бягучага адліку лініі затрымкі гэтыя рэгістры аказваюцца вольныя ад папярэдніх значэнняў.
Вынік дадзенага этапу паказаны ніжэй. Рэкамендуецца гэтыя змены таксама захаваць у асобным файле (напрыклад, з імем «convolution_my_5.asm»).
; Цыкл вылічэнні скруткі; for (count = lenFir - 1; count> = 0; count -) {; Вызначэнне пачатковага значэння зменнай цыклу SUB .L2 lenFir_B, 1, count_B; 1-8 ітэрацыі цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ; 1 LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 2 LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 3 [count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 4 [count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 5 [count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 6 MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 7 MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 8 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 9 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B; 10 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B; 11 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 12 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 13 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 14 ADD .S1 summa_A, mpy_A, summa_A; 15 ADD .S1 summa_A, mpy_A, summa_A; Тыя, што засталіся ітэрацыі цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;;;;;;;;; loop01:; Кропка вяртання пры цыклічных вылічэннях; Чытанне адліку simpl = * pSimplBuff ++; ; Чытанне каэфіцыента coeff = * pCoeffBuff ++; LDH .D2T2 * pCoeffBuff_B ++, coeff_B; coeff = * pCoeffBuff ++; || LDH .D1T1 * pSimplBuff_A ++, simpl_A; simpl = * pSimplBuff ++; NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці NOP; Чаканне завяршэння аперацыі чытання; дадзеных з памяці; Множанне каэфіцыента на адлік MPY .M1X coeff_B, simpl_A, mpy_A; mpy = coeff * simpl; NOP; Чаканне завяршэння аперацыі множання ADD .S1 summa_A, mpy_A, summa_A; summa + = mpy; ; } Канец цыклу вылічэнні скруткі
- Арганізацыя цыклічных вылічэнняў на базе канвеера. У блоку каманд № 8 першых 8 ітэрацый цыклічных вылічэнняў (гл. П. 3) выконваюцца ўсе каманды аднаго кроку цыклу (за выключэннем аперацыі пераходу). Гэты блок будзе ядром цыкла з канвеерам. Усе блокі каманд да негоэто пралог цыклу, пасля - эпілог.
Для арганізацыі цыклічных вылічэнняў на базе канвеера неабходна (у разгляданым прыкладзе) выключыць з праграмнага кода блок каманд «Пакінутыя ітэрацыі цыклу» (гл. П. 3). Затым ўсталяваць пазнаку для пераходу пры цыклічных вылічэннях, а таксама ў эпілогу і ядры цыкла неабходна дадаць каманды пераходу. Вынік пераўтварэнні кода:
; Цыкл вылічэнні скруткі; for (count = lenFir - 1; count> = 0; count -) {; Вызначэнне пачатковага значэння зменнай цыклу SUB .L2 lenFir_B, 8, count_B; Пралог цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;; ; 1 LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 2 LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 3 [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 4 [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 4 [count_B] B .S2 loop01 || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 6 [count_B] B .S2 loop01 || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; 7 [count_B] B .S2 loop01 || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; Ядро цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;;;; ; 8 loop01: [count_B] B .S2 loop01 || ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B || LDH .D2T2 * pCoeffBuff_B ++, coeff_B || LDH .D1T1 * pSimplBuff_A ++, simpl_A; Эпілог цыклу ;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;;;;;;;;;;;; ; 9 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B; 10 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A || [Count_B] SUB .L2 count_B, 1, count_B; 11 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 12 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 13 ADD .S1 summa_A, mpy_A, summa_A || MPY .M1X coeff_B, simpl_A, mpy_A; 14 ADD .S1 summa_A, mpy_A, summa_A; 15 ADD .S1 summa_A, mpy_A, summa_A; } Канец цыклу вылічэнні скруткі
Рэкамендуецца захаваць дадзены варыянт зьмяняй кода ў асобным файле (напрыклад, з імем «convolution_my_6.asm»). У 8-м блоку каманд з'явілася пазнака «loop01» для арганізацыі цыкла, а таксама каманда ўмоўнага пераходу на гэтую пазнаку ([count_B] B .S2 loop01), выкананая паралельна з астатнімі камандамі блока. Дадзеная каманда будзе выканана толькі праз 5 тактаў. Таму неабходна за 5 тактаў да блока каманд ядра паставіць першую аперацыю ўмоўнага пераходу (блок каманд нумар 3) - гэтая каманда пераходу будзе выканана толькі пасля 8-га блока каманд.
Каманда пераходу ў 4-м блоку каманд будзе выканана пасля таго, як 8-ы блок будзе паўтораны двойчы. Затым будзе выканана каманда пераходу 5-га блока, затым 6-га, 7-га, і толькі пасля гэтага пачне выконвацца каманда пераходу ядра цыклу.
Затрымка выканання аперацыі ўмоўнага пераходу прыводзіць да таго, што пасля забароны на выкананне ўмоўнага пераходу ў ядры цыклу (значэнне рэгістра ўмовы «count_B» роўна нулю), пераход будзе ажыццёўлены яшчэ 5 разоў (будуць выконвацца папярэднія каманды пераходу). Гэта цягне неабходнасць, па-першае, паменшыць значэнне зменнай цыклу «count_B» яшчэ на 7 адзінак:
SUB .L2 lenFir_A, 8, count_B,
па-другое, заблакаваць декрементацию зменнай цыклу пасля дасягнення значэння «нуль»:
[Count_B] SUB .L2 count_B, 1, count_B.
Памяншэнне зменнай цыклу на 7 адзінак абумоўлена тым, што выкананне 7 ітэрацый адбываецца па-за ядром цыклу (у пралогу і эпілогу).
Адкампіляваць праект, запусціць яго на выкананне і пераканацца ў карэктнай працы. Такім чынам, атрыманы праграмны код цыклічных вылічэнняў, аптымізаваны з выкарыстаннем канвеернай і паралельнай апрацоўкі каманд.
У наступным артыкуле будзе паказана, як выкарыстоўваць магчымасці RTDX для паскарэння і візуалізацыі працэсу адладкі, а таксама кантролю часу выканання праграмнага кода.
Ігар ДУК