Оптимізація продуктивності запитів SQL Server
- Аналіз планів виконання
- Оцінка вартості виконання
- Аналіз плану виконання
- Вправа. Запит замовлення покупця
- індекс покриття
- індексовані уявлення
- Пошук запитів, які потребують в налаштуванні
В процесі оптимізації сервера бази даних потрібно налаштування продуктивності окремих запитів. Це так само (а може бути, і більше) важливо, ніж встановлювати інші елементів, які впливають на продуктивність сервера, наприклад конфігурації апаратного та програмного забезпечення.
Навіть якщо сервер бази даних використовує найпотужніше апаратне забезпечення на світлі, жменька погано себе провідних запитів може погано відбитися на його продуктивності. Фактично, навіть один невдалий запит (іноді їх називають «вийшли з-під контролю») може викликати серйозне зниження продуктивності бази даних.
Навпаки, тонка настройка набору найбільш дорогих або часто виконуваних запитів може сильно підвищити продуктивність бази даних. У цій статті я планую розглянути деякі технології, які можна використовувати для ідентифікації або тонкої настройки найдорожчих і погано працюють запитів до сервера.
Аналіз планів виконання
Зазвичай при налаштуванні окремих запитів варто почати з розгляду плану виконання запиту. У ньому описана послідовність фізичних і логічних операцій, які SQL ServerTM використовує для виконання запиту і виведення бажаного набору результатів. План виконання створює в фазі оптимізації обробки запиту компонент ядра бази даних, який називається оптимізатором запитів, беручи до уваги багато різних факторів, наприклад використані в запиті предикати пошуку, задіяні таблиці і умови об'єднання, список повернутих стовпців і наявність корисних індексів, які можна використовувати в як ефективних шляхів доступу до даних.
У складних запитах кількість всіх можливих перестановок може бути величезним, тому оптимізатор запитів не оцінює всі можливості, а намагається знайти «відповідний» для даного запиту шлях. Справа в тому, що знайти ідеальний план можливо не завжди. Навіть якби це було можливо, вартість оцінки всіх можливостей при розробці ідеального плану легко переважила б весь виграш в продуктивності. З точки зору адміністратора бази даних важливо зрозуміти процес і його обмеження.
Існує кілька способів вилучення плану виконання запиту:
- У Management Studio є функції відображення реального і приблизного плану виконання, що представляють план в графічній формі. Це найбільш зручна можливість безпосередньої перевірки і, за великим рахунком, найбільш часто використовуваний спосіб відображення та аналізу планів виконання (приклади з цієї статті я буду ілюструвати графічними планами, створеними саме таким способом).
- Різні параметри SET, наприклад, SHOWPLAN_XML і SHOWPLAN_ALL, повертають план виконання у вигляді документа XML, що описує план у вигляді спеціальної схеми, або набору рядків з текстовим описом кожної операції.
- Класи подій профайлера SQL Server, наприклад, Showplan XML, дозволяють збирати плани виконання виразів методом трасування.
Хоча XML-представлення плану виконання не найзручніший для користувача формат, ця команда дозволяє використовувати самостійно написані процедури і службові програми для аналізу, пошуку проблем з продуктивністю і практично оптимальних планів. Подання на базі XML можна зберегти в файл з розширенням sqlplan, відкривати в Management Studio та створювати графічне представлення. Крім того, ці файли можна зберігати для подальшого аналізу без необхідності відтворювати їх щоразу, як цей аналіз знадобиться. Це особливо корисно для порівняння планів і виявлення виникаючих з часом змін.
Оцінка вартості виконання
Перше, що потрібно зрозуміти - це як генеруються плани виконання. SQL Server використовує оптимізатор запиту на основі вартості, тобто намагається створити план виконання з мінімальною оцінною вартістю. Оцінка проводиться на основі статистики розподілу доступних оптимізатора на момент перевірки кожної використаної в запиті таблиці даних. Якщо такої статистики немає або вона вже застаріла, оптимізаторові запиту не вистачить необхідної інформації і оцінка, швидше за все, виявиться неточною. У таких випадках оптимізатор переоцінить або недооцінив вартість виконання різних планів і вибере не найоптимальніший.
Існує кілька поширених, але хибних уявлень про приблизну вартість виконання. Особливо часто вважається, що приблизна вартість виконання є хорошим показником того, скільки часу займе виконання запиту і що ця оцінка дозволяє відрізнити хороші плани від поганих. Це не вірно. По-перше, є багато документів, що стосуються того, в яких одиницях виражається приблизна вартість і чи мають вони безпосередній стосунок до часу виконання. По-друге, оскільки значення це приблизно та може виявитися помилковим, плани з великими оціночними затратами іноді виявляються значно ефективніше з точки зору ЦП, введення / виведення і часу виконання, незважаючи на приблизно високу вартість. Це часто трапляється з запитами, де задіяні табличні змінні. Оскільки статистики по ним не існує, оптимізатор запитів часто передбачає, що в таблиці є всього один рядок, хоча їх у багато разів більше. Відповідно, оптимізатор вибере план на основі неточної оцінки. Це означає, що при порівнянні планів виконання запитів не слід покладатися тільки на приблизну вартість. Включіть в аналіз параметри STATISTICS I / O і STATISTICS TIME, щоб визначити справжню вартість виконання в термінал введення / виведення і часу роботи ЦП.
Тут варто згадати про особливий тип плану виконання, який називається паралельним планом. Такий план можна вибрати при відправці на сервер з декількома ЦП запиту, піддається паралелізації (В принципі, оптимізатор запиту розглядає використання паралельного плану тільки в тому випадку, якщо вартість запиту перевищує певний настроюється значення.) Через додаткових витрат на управління декількома паралельними процесами виконання , пов'язаними з розподілом завдань, виконанням синхронізації і зведенням результатів, паралельні плани обходяться дорожче, що відображає їх приблизна вартість. Тоді чому ж вони краще дешевших, що не паралельних планів? Завдяки використанню обчислювальної потужності декількох ЦП паралельні плани зазвичай видають результат швидше, ніж стандартні. Залежно від конкретного сценарію (включаючи такі змінні, як доступність ресурсів з паралельної навантаженням інших запитів) ця ситуації для кого-то може виявитися бажаною. Якщо це ваш випадок, потрібно буде вказати, які з запитів можна виконувати за паралельним плану і скільки ЦП може задіяти кожен. Для цього потрібно налаштувати максимальну ступінь паралелізму на рівні сервера і при необхідності налаштувати обхід цього правила на рівні окремих запитів за допомогою параметра OPTION (MAXDOP n).
Аналіз плану виконання
Тепер розглянемо простий запит, його план виконання і деякі способи підвищення продуктивності. Припустимо, що я виконую цей запит в Management Studio з включеним параметром включення реального плану виконання в прикладі бази даних Adventure Works SQL Server 2005: Додати
SELECT c.CustomerID, SUM (LineTotal) FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader oh ON od.SalesOrderID = oh.SalesOrderID JOIN Sales.Customer c ON oh.CustomerID = c.CustomerID GROUP BY c.CustomerID
У підсумку я бачу план виконання, зображений на рис. 1. Цей простий запит обчислює загальну кількість замовлень, розміщених кожним клієнтом в базі даних Adventure Works. Дивлячись на цей план, ви бачите, як ядро бази даних обробляє запити і видає результат. Графічні плани виконання читаються зверху вниз, справа наліво. Кожен значок відповідає виконаній логічної або фізичної операції, а стрілки - потокам даних між операціями. Товщина стрілок відповідає кількості переданих рядків (чим товще, тим більше). Якщо помістити курсор на один із значків оператора, з'явиться жовта підказка (така, як на рис. 2) з відомостями про дану операцію.
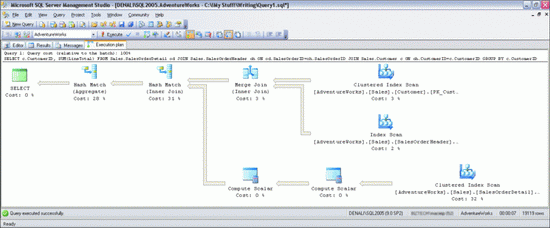
Мал. 1 Приклад плану виконання

Мал. 2 Відомості про операцію
Дивлячись на оператори, можна аналізувати послідовність виконаних етапів:
- Ядро бази даних виконує операцію сканування кластерізірованних індексів з таблицею Sales.Customer і повертає стовпець CustomerID з усіма рядками з цієї таблиці.
- Потім воно виконує сканування індексів (НЕ кластерізірованних) над одним з індексів з таблиці Sales.SalesOrderHeader. Це індекс стовпця CustomerID, але мається на увазі, що в нього входить стовпець SalesOrderID (ключ кластеризації таблиці). Сканування повертає значення обох стовпців.
- Результати обох сеансів сканування об'єднуються в стовпці CustomerID за допомогою фізичного оператора злиття (це один з трьох можливих фізичних способів виконання операції логічного об'єднання. Операція виконується швидко, але вхідні дані доводиться сортувати в об'єднаному стовпці. В даному випадку обидві операції сканування вже повернули рядки, розсортовані в стовпці CustomerID, так що додаткову сортування виконувати не потрібно).
- Потім ядро бази даних виконує сканування кластерізірованного індексу в таблиці Sales.SalesOrderDetail, витягуючи значення чотирьох стовпців (SalesOrderID, OrderQty, UnitPrice і UnitPriceDiscount) з усіх рядків таблиці (передбачалося, що повернуто буде 123,317 рядків. Як видно з властивостей Estimated Number of і and Actual Number of Rows на рис. 2, вийшло саме це число, так що оцінка виявилася дуже точною).
- Рядки, отримані при скануванні кластерізованного індексу, передаються оператору обчислення вартості, помноженої на коефіцієнт, щоб обчислити значення стовпця LineTotal для кожного рядка на основі стовпців OrderQty, UnitPrice і UnitPriceDiscount, згаданих у формулі.
- Другий оператор обчислення вартості, помноженої на коефіцієнт, застосовує до результату попереднього обчислення функцію ISNULL, як і передбачає формула обчисленого стовпчика. Він завершує обчислення в стовпці LineTotal і повертає його наступного оператору разом зі стовпцем SalesOrderID.
- Висновок оператора злиття з етапу 3 об'єднується з висновком оператора вартості, помноженої на коефіцієнт з етапу 6 і використанням фізичного оператора збігу значень хеша.
- Потім до групи рядків, повернутих оператором злиття за значенням стовпця CustomerID і обчисленому зведеному значенням SUM стовпчика LineTotal застосовується інший оператор збігу значень хеша.
- Останній вузол, SELECT - це не фізичний або логічний оператор, а местозаполнітель, відповідний зведеним результатами запиту і вартості.
У створеному на моєму ноутбуці плані виконання приблизна вартість дорівнювала 3,31365 (як видно на рис. 3). При виконанні з активним з'єднанням STATISTICS I / O ON звіт за запитом містив згадування про 1,388 логічних операціях читання з трьох задіяних таблиць. Процентне значення під кожним оператором - це його вартість в процентах від загальної приблизної вартості всього плану. На плані на рис. 1 видно, що більша частина загальної вартості пов'язана з наступними трьома операторами: сканування кластерізованного індексу таблиці Sales.SalesOrderDetail і два оператора збігу значень хеша. Перед тим як приступити до оптимізації, хотілося відзначити одне дуже просте зміна в моєму запиті, яке дозволило повністю усунути два оператора.

Мал. 3 Загальна приблизна вартість виконання запиту
Оскільки я повертав з таблиці Sales.Customer тільки стовпець CustomerID, і той же стовпець включений в таблицю Sales.SalesOrderHeaderTable як зовнішній ключ, я можу повністю виключити з запиту таблицю Customer без зміни логічного значення або результату нашого запиту. Для цього використовується наступний код:
SELECT oh.CustomerID, SUM (LineTotal) FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader oh ON od.SalesOrderID = oh.SalesOrderID GROUP BY oh.CustomerID
Вийшов другий план виконання, який зображений на рис. 4.

Мал. 4 План виконання після усунення з запиту таблиці Customer
Повністю усунені дві операції - сканування кластерізірованного індексу таблиці Customer і злиття Customer і SalesOrderHeader, а збіг значень хеша замінено на куди більш ефективну операцію злиття. При цьому для злиття таблиць SalesOrderHeader і SalesOrderDetail потрібно повернути рядки обох таблиць, розсортовані за загальним колонки SalesOrderID. Для цього оптимізатор кластера виконав сканування кластерізованного індексу таблиці SalesOrderHeader замість того, щоб використовувати сканування некластерізованний індексу, який був би дешевше з точки зору введення / виводу. Це хороший приклад практичного застосування оптимізатора запиту, оскільки економія, що виходить при зміні фізичного способу злиття, виявилася більшою додаткової вартості введення / виведення при скануванні кластерізованного індексу. Оптимізатор запиту вибрав вийшла комбінацію операторів, оскільки вона дає мінімально можливу приблизну вартість виконання. На моєму комп'ютері, незважаючи на те, що кількість логічних зчитувань зросла (до 1,941), тимчасові витрати ЦП стали менше, і приблизна вартість виконання даного запиту впала на 13 відсотків (2,89548).
Припустимо, що я хочу ще поліпшити продуктивність запиту. Я звернув увагу на сканування кластерізованного індексу таблиці SalesOrderHeader, яке тепер є найдорожчим оператором плану виконання. Оскільки для виконання запиту потрібно всього два стовпці, можна створити некластерізованний індекс, де містяться лише ці два стовпці. Таким чином, замість сканування всієї таблиці можна буде просканувати індекс набагато меншого розміру. Визначення індексу може виглядати приблизно так:
CREATE INDEX IDX_OrderDetail_OrderID_TotalLine ON Sales.SalesOrderDetail (SalesOrderID) INCLUDE (LineTotal)
Зверніть увагу, що в створеному індексі є обчислений стовпець. Це можливо не завжди - все залежить від визначення такого стовпчика.
Створивши цей індекс і виконавши той же запит, я отримав новий план, який зображений на рис. 5.

Мал. 5 Оптимізований план виконання
Сканування кластерізованного індексу таблиці SalesOrderDetail замінено некластерізованний скануванням з помітно меншими витратами на введення / висновок. Крім того, я виключив один з операторів обчислення вартості, помноженої на коефіцієнт, оскільки в моєму індексі вже є обчислене значення стовпця LineTotal. Тепер приблизна вартість плану виконання становить 2,28112 і при виконанні запиту здійснюється 1,125 логічних зчитувань.
Вправа. Запит замовлення покупця
Питання. Ось приклад запиту замовлення покупця. Спробуйте отримати визначення індексу: з'ясуйте, наявність яких стовпців перетворить його в індекс покриття даного запиту і чи вплине порядок стовпців на продуктивність.
Відповідь. Я запропонував розрахувати оптимальний індекс покриття для створення таблиці Sales.SalesOrderHeader на прикладі запиту з моєї статті. При цьому потрібно в першу чергу відзначити, що запит використовує тільки два стовпці з таблиці: CustomerID і SalesOrderID. Якщо ви уважно прочитали цю статтю, то помітили, що у випадку з таблицею SalesOrderHeader індекс покриття запиту вже існує, це індекс CustomerID, який побічно містить стовпець SalesOrderID, що є ключем кластеризації таблиці.
Звичайно, я пояснював і то, чому оптимізатор запиту не став використовувати цей індекс. Так, можна змусити оптимізатор запиту використовувати цей індекс, але це рішення було б менш ефективним, ніж існуючий план з операторами сканування кластерізованного індексу і злиття. Справа в тому, що оптимізатор запиту довелося б примусити або виконати додаткову операцію сортування, необхідну для використання злиття, або відкотитися назад, до використання менш ефективного оператора збігу значень хеша. В обох варіантах приблизна вартість виконання вище, ніж в існуючому плані (версія з оператором сортування працювала б особливо погано), тому оптимізатор запиту не буде їх використовувати без примусу. Отже, в даній ситуації краще сканування кластерізованного індексу буде працювати тільки некластерізованний індекс в шпальтах SalesOrderID, CustomerID. При цьому потрібно зазначити, що стовпці повинні йти саме в такому порядку:
CREATE INDEX IDX_OrderHeader_SalesOrderID_CustomerID ON Sales.SalesOrderHeader (SalesOrderID, CustomerID)
Якщо ви створите цей індекс, в плані виконання буде використаний не сканування кластерізованного індексу, а сканування індексу. Різниця суттєва. В даному випадку некластерізованний індекс, який містить тільки два стовпці, помітно менше всієї таблиці у вигляді кластерізованного індексу. Відповідно, при зчитуванні потрібних даних буде менше задіяний введення / виведення.
Також цей приклад показує, що порядок стовпців у вашому індексі може істотно вплинути на його ефективність для оптимізатора запитів. Створюючи індекси з декількома стовпцями, обов'язково майте це на увазі.
індекс покриття
Індекс, Створений з табліці SalesOrderDetail, представляет собою так звань «індекс покриття». Це некластерізованній індекс, де містяться всі стовпці, необхідні для Виконання запиту. Він усуває необхідність сканування всієї таблиці за допомогою операторів сканування таблиці або кластерізованного індексу. По суті індекс являє собою зменшену копію таблиці, де міститься підмножина її стовпців. В індекс включаються тільки стовпці, які необхідні для відповіді на запит або запити, тобто тільки те, що «покриває» запит.
Створення індексів покриття найбільш частих запитів - один з найпростіших і розповсюджених способів тонкої настройки запиту. Особливо добре він працює в ситуаціях, коли в таблиці кілька стовпців, але запити часто посилаються тільки на деякі з них. Створивши один або кілька індексів покриття, можна значно підвищити продуктивність відповідних запитів, так як вони будуть звертатися до помітно меншій кількості даних і, відповідно, кількість вводів / висновків скоротиться. Проте, підтримка додаткових індексів в процесі модифікації даних (оператори INSERT, UPDATE і DELETE) має на увазі деякі витрати. Слід чітко визначити, чи виправдовує збільшення продуктивності ці додаткові витрати. При цьому врахуйте характеристики свого середовища і співвідношення кількості запитів SELECT і змін даних.
Не бійтеся створювати індекси з декількома стовпцями. Вони бувають значно корисніше індексів з одним стовпцем, і оптимізатор запитів частіше їх використовує для покриття запиту. Більшість індексів покриття містить декілька стовпців.
З моїм прикладом запиту можна зробити ще дещо. Створивши індекс покриття таблиці SalesOrderHeader, можна розраховувати для запит. При цьому буде використано сканування некластерізованний індексу замість кластерізованного. Пропоную вам виконати цю вправу самостійно. Спробуйте отримати визначення індексу: з'ясуйте, наявність яких стовпців перетворить його в індекс покриття даного запиту і чи вплине порядок стовпців на продуктивність. Рішення см. В бічній панелі "Вправа. Запит замовлення покупця".
індексовані уявлення
Якщо виконання мого прикладу запиту дуже важливо, я можуть піти трохи далі і створити індексовані уявлення, в якому фізично зберігаються матеріалізовані результати запиту. При створенні індексованих уявлень існують деякі попередні умови і обмеження, але якщо їх вдасться використовувати, продуктивність сильно підвищиться. Зверніть увагу, що витрати на обслуговування індексованих уявлень вище, ніж у звичайних індексів. Їх потрібно використовувати з обережністю. В даному випадку визначення індексу виглядає приблизно так:
CREATE VIEW vTotalCustomerOrders WITH SCHEMABINDING AS SELECT oh.CustomerID, SUM (LineTotal) AS OrdersTotalAmt, COUNT_BIG (*) AS TotalOrderLines FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader oh ON od.SalesOrderID = oh.SalesOrderID GROUP BY oh.CustomerID
Зверніть увагу на параметр WITH SCHEMABINDING, без якого неможливо створити індекс такого уявлення, і функцію COUNT_BIG (*), яка буде потрібно в тому випадку, якщо в нашому визначенні індексу міститься узагальнена функція (в даному випадку SUM). Створивши це уявлення, я можу створити і індекс:
CREATE UNIQUE CLUSTERED INDEX CIX_vTotalCustomerOrders_CustomerID ON vTotalCustomerOrders (CustomerID)
При створенні цього індексу результат запиту, включеного в визначення уявлення, матеріалізується і фізично зберігається на вказаному диску. Зверніть увагу, що всі операції модифікації даних вихідної таблиці автоматично оновлюють значення уявлення на основі визначення.
Якщо перезапустити запит, то результат буде залежати від використовуваної версії SQL Server. У версіях Enterprise або Developer оптимізатор автоматично порівняє запит з визначенням індексованого подання і використовує це уявлення, замість того щоб звертатися до вихідної таблиці. На рис. 6 наведено приклад отриманого плану виконання. Він складається з однієї-єдиної операції - сканування кластерізованного індексу, який я створив на основі подання. Приблизна вартість виконання становить всього 0,09023 і при виконанні запиту здійснюється 92 логічних зчитування.

Мал. 6 План виконання при використанні індексованого подання
Це індексовані уявлення можна створювати і використовувати і в інших версіях SQL Server, але для отримання аналогічного ефекту необхідно змінити запит і додати пряме посилання на представлення за допомогою підказки NOEXPAND, приблизно так:
SELECT CustomerID, OrdersTotalAmt FROM vTotalCustomerOrders WITH (NOEXPAND)
Як бачите, правильно використані індексовані уявлення можуть виявитися дуже потужними знаряддями. Найкраще їх використовувати в оптимізованих запитах, що виконують агрегування великих обсягів даних. У версії Enterprise можна вдосконалити багато запитів, не змінюючи коду.
Пошук запитів, які потребують в налаштуванні
Як я визначають, що запит варто налаштувати? Я шукаю часто виконуються запити, можливо, з невисокою вартістю виконання в окремому випадку, але в цілому дорожчі, ніж великі, але рідко зустрічаються запити. Це не означає, що останні налаштовувати не потрібно. Я просто вважаю, що для початку потрібно зосередитися на більш частих запитах. Так як же їх знайти?
На жаль, найнадійніший метод досить складний і передбачає відстеження усіх виконаних запитів до сервера з наступний угрупованням за підписами. При цьому текст запиту з реальними значеннями параметрів замінюється на заміну тексту, який дозволяє вибрати однотипні запити з різними значеннями. Підписи запиту створити важко, так що це складний процес. Іцик Бен-Ган (Itzik Ben-Gan) описує рішення з використанням призначених для користувача функцій в середовищі CLR і регулярних виразів в своїй книзі «Microsoft SQL Server 2005 зсередини: запити T-SQL».
Існує ще один метод, набагато простіший, але не настільки надійний. Можна покластися на статистику всіх запитів, яка зберігається в кеші плану виконання, і опитати їх з використанням динамічних адміністративних уявлень. На малюнку 7 є приклад запиту тексту і плану виконання 20 запитів з кешу, у яких загальна кількість логічних зчитувань виявилося максимальним. За допомогою цього запиту дуже зручно швидко знаходити запити з максимальною кількістю логічних зчитувань, але є і деякі обмеження. Він відображає тільки запити з планами, кешуватися на момент запуску. Чи не кешированниє об'єкти не відображаються.
Мал. 7 Пошук 20 найдорожчих з точки зору введення / виводу при зчитуванні запитів.
SELECT TOP 20 SUBSTRING (qt.text, (qs.statement_start_offset / 2) +1, ((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH (qt.text) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) +1 ), qs.execution_count, qs.total_logical_reads, qs.last_logical_reads, qs.min_logical_reads, qs.max_logical_reads, qs.total_elapsed_time, qs.last_elapsed_time, qs.min_elapsed_time, qs.max_elapsed_time, qs.last_execution_time, qp.query_plan FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text (qs.sql_handle) qt CROSS APPLY sys.dm_exec_query_plan (qs.plan_handle) qp WHERE qt.encrypted = 0 ORDER BY qs.total_logical_reads DESC
Виявивши запити з поганою продуктивністю, розгляньте їх плани і знайдіть способи оптимізації за допомогою технологій індексування, які я описав в цій статті. Ви не дарма витратите час, якщо досягнете успіху.
Вдалині настройки!
Тоді чому ж вони краще дешевших, що не паралельних планів?Так як же їх знайти?