LSI в SEO: розкладаємо по поличках. Як використовувати тематичні слова ефективно
- Витримка: що оптимізатори і копірайтери думають про LSI
- Що таке LSI насправді?
- Недоліки LSI як методу оцінки змісту тексту
- Що потрібно розуміти, приступаючи до LSI-копірайтингу
- Як правильно готувати LSI-тексти?
- Мій варіант використання LSI
- Завершальний етап: підсилюємо текст новими розширеннями
- Короткі висновки для тих, хто перегорнув, не читаючи
Ось уже кілька років LSI-копірайтинг (використання в SEO-текстах «слів, які задають тематику») залишається вкрай модною тенденцією. За цей час здорова в основі ідея встигла обрости міфами і надто сміливими трактуваннями.
Витримка: що оптимізатори і копірайтери думають про LSI
Якщо читати підряд всі, що написано по темі, то вимальовуються наступні тези.
- Абревіатура розшифровується як latent semantic indexing - приховане семантичне індексування.
- Текст для просування повинен включати тематичні слова, а не тільки ключові.
- До LSI-слів належать а) синоніми основного ключового слова б) слова, які характеризують і доповнюють основний ключевик в) інші слова, що мають відношення до теми статті.
- LSI - це спеціальний новий алгоритм пошукових систем проти поганих SEO-текстів, «нова ера в копірайтингу».
- Також алгоритм потрібен щоб відрізняти тексти за змістом. Наприклад, щоб розділити опис фільму «Тачки» від характеристик садового інвентарю.
- А ще LSI-текст повинен мати структуру, бути написаним простою мовою, мати приємний ритм, правильно розподіляти ключові слова і тематичні розширення. Інформація повинна бути подана на рівні експерта без граматичних і орфографічних помилок.
- Щоб знайти LSI, можна використовувати підказки пошукової системи, підсвічування на видачу, аналіз текстів конкурентів (і сервіси, які все це автоматизують).
- Подекуди навіть проскакують заголовки «LSI вбило SEO!» ( посилання, яку я автоматично вставляю після чергових похорону моєї професії ).
Я тільки що заощадив вам кілька годин на перелопачування десятків статей по темі. Тепер спробуємо розібратися, що тут правда, а що міф. А головне - як можна використовувати це знання на практиці.
Що таке LSI насправді?
Ось короткий і академічно точну відповідь:
LSI - сингулярне розкладання терм-документної матриці.
Це відео стало сеошним мемом - нагромадження термінології викликає сміх. На мій погляд, досить дивно боятися незнайомих термінів, якщо під рукою є Google. Щоб розібратися в матчастини на побутовому рівні, не треба бути професором.
Наприклад, можете почитати статтю «Тематичне моделювання текстів на природній мові» (автори Антон Коршунов, Андрій Гомзін), вона розкриває цю та кілька суміжних тем на вельми доступному рівні. Наведу кілька ключових цитат.
Спочатку про важливість методу:
Найчастіше документи, релевантні запиту з точки зору користувача, не містили термінів із запиту і тому не відображалися в результатах пошуку (проблема синонімії). З іншого боку, велика кількість документів, слабо або зовсім не відповідають запиту, показувалися користувачеві тільки тому, що містили терміни із запиту (проблема полісемії).
У 1988 р Dumais et al запропонували метод латентно-семантичного індексування (latent semantic indexing, LSI), покликаний підвищити ефективність роботи інформаційно-пошукових систем шляхом проектування документів і термінів в простір більш низької розмірності, яке містить семантичні концепції вихідного набору документів.
А тепер про те, як він реалізується.
Вихідна точка - це терм-документная матриця:
Елементи цієї матриці містять ваги термінів у документах, призначені за допомогою обраної ваговій функції. Як приклад можна розглянути найпростіший варіант такої матриці, в якій вага терміна дорівнює 1, якщо він зустрівся в документі (незалежно від кількості появ), і 0 якщо не зустрівся.
 d1-d6 - документи, в першому стовпці - терміни
d1-d6 - документи, в першому стовпці - терміни
Легко бачити, що деякі терміни зустрічаються разом в одному документі а інші - ні. Пошукові системи мають базу текстів, яка в повній мірі відображає особливості природної мови. Це дозволяє створювати величезні терм-документні матриці і на їх основі робити достовірні висновки про взаємозв'язки між словами і приналежності текстів до тієї чи іншої тематики.
Однак величезний розмір гарний тільки в плані статистичної достовірності. Безпосередньо працювати з матрицею, яка отримана з мільярдів текстів, неможливо, так як вимагає занадто великих машинних ресурсів. Ось тут і потрібно сингулярне розкладання - математична операція, яка дозволяє спростити терм-документную матрицю, виділивши з неї тільки найбільш значущі тенденції. Це і є «проекція в простір більш низької розмірності, яке містить семантичні концепції вихідного набору документів».
(З матчастиною практично закінчили, далі піде ближче до практики. Якщо цікавлять деталі - зверніться до статті на habrahabr , Де розібраний простий робітник приклад і показані етапи розкладання).
Для нас найбільше важлива остання цитата, яка пояснює кінцеву мету всіх цих процедур з точки зору пошукової системи:
Для задач інформаційного пошуку запит користувача розглядається як набір термінів, який проектується в семантичний простір, після чого отримане уявлення порівнюється з уявленнями документів в колекції.
Саме так і можна знайти документ, який релевантний за змістом, хоча і не містить ключових слів запиту, тобто не володіє текстової релевантність в класичному розумінні .
А ще пошукова система може порівняти уявлення тексту конкретної сторінки з еталонними документами конкретної тематики. Якщо вони будуть сильно відрізнятися - це серйозний сигнал про те, що з текстом щось не так.
Наприклад, типовий SEO-текст зразка 2008 року складається з «води» і спеціально вставлених ключових слів. «Вода» в нашому семантичному просторі буде штовхати текст до документів загальної тематики, а ключові слова - навпаки до конкретної теми. Ця невідповідність не так складно виявити.

Недоліки LSI як методу оцінки змісту тексту
Навіть після поверхневого знайомства з методом, ви обов'язково помітите, що LSI - це не магія, а всього лише методика аналізу текстів. Більш того, вона має ряд недоліків і спрощень:
- Текст в цьому методі розглядається просто як «мішок слів». Ігнорується їх порядок і взаємозв'язку в реченні.
- Вважається, що слово має єдине значення.
- Сенс природного тексту не обов'язково збігається зі значенням набору слів. Іносказання, іронія, підтекст такий спосіб не розпізнаються.
- Сингулярне розкладання дозволяє працювати тільки з найбільш значущими складовими вихідної матриці. Частина даних при цьому все одно втрачається.
Чому я загострюю на цьому увагу? Тому що тепер ми бачимо повну картину і нарешті можемо зробити кілька важливих проміжних висновків. Повернемося до початку статті і тверезо подивимося на найпоширеніші переконання. Отже.
Що потрібно розуміти, приступаючи до LSI-копірайтингу
По-перше, не варто думати, що LSI - це чарівна таблетка.
Цілком очевидно, що пошукові системи використовують безліч методик для визначення «спамності» або «корисності» тексту. Приховане семантичне індексування не універсальна, у нього є недоліки. Пошуковики безумовно знають про них і застосовують LSI в комплексі з іншими факторами. Наприклад, величезна кількість даних про якість тексту дають поведінкові метрики.
Так що просто натякають в водянистий текст тематичних слів - не найкраща стратегія в довгостроковій перспективі.
По-друге, немає сенсу прирівнювати написання хороших текстів до LSI-копірайтингу.
А саме це і відбувається. Ось скріншот з Вікіпедії про LSI-копірайтингу: 
Навіщо прісобачівать принципи, відомі з часів так Гомера, до однієї вузької методикою?
По-третє, LSI в чистому вигляді - історія в першу чергу про «вгадування» сенсу запиту, класифікацію документів за темами і фільтрацію спаму, і тільки в другу - про ранжування.
нещодавно робив конспект доповідей про пристрій Яндекса . Там є дуже показовий момент. Олександр Сафронов розповідає про напрямки з лінгвістики для поліпшення якості пошуку. У тому числі про синоніми та про пов'язаних розширеннях, уточнень, схожих запитах. Те й інше прийнято об'єднувати під ярликом «LSI». Але!
Розпізнавання синонімів - це більшою мірою «біль» самої пошукової системи. Там розуміють, що текст може бути якісним і релевантним, навіть не включаючи всі варіанти. Наприклад сторінка з входженням «купити» може пристойно ранжуватися по ключам «покупка», «придбати» і так далі.
А ось про розширення запиту Олександр Сафронов чітко говорить:
Швидше за все, релевантний документ, крім слів запиту, буде містити ці додаткові слова (якщо він дійсно добре відповідає на запит користувача).
Приклад додаткових слів: 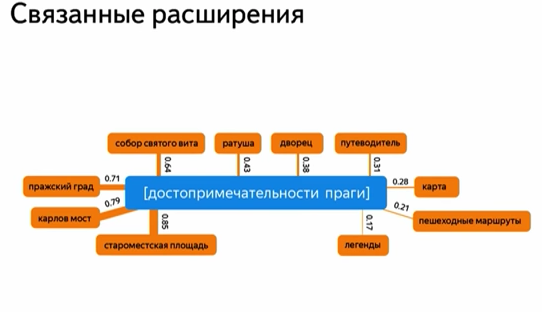
Зауважте, до речі, що тут ми бачимо зв'язку не тільки між окремими словами. Тому очевидно, що для виділення розширень використовується інша методика, а не LSI.
Другий нюанс в тому, що базою для їх отримання є не тільки колекція текстів, а й пошукові запити. Їх використання - це можливість для пошукача шукати зв'язки не за формальними критеріями (чи зустрічаються в одному тексті чи ні). Варіант: аналіз зв'язків між групою запитів, яку задав один користувач в короткий проміжок часу (зрозуміло, з об'єднанням даних по мільйонам користувачів).
По-четверте, для знаходження LSI потрібні алгоритми, що працюють з досить великим обсягом тексту.
Найпростіший і часто пропонований шлях - парсити підсвічування Яндекса - і завжди працював не дуже добре, даючи дуже убогий спектр слів, зараз взагалі малоактуален.
По-п'яте, слова, які пропонують послуги, не є результатом «справжнього» LSI, з яким працюють пошукові системи (далі ця обмовка не береться для стислості і як данина сформованим поняттям).
Пункт прямо випливає з попереднього. Очевидно, що сервіси не мають всіх можливостей пошукової системи. Або, принаймні, не знають, на який колекції документів він визначає закономірності для себе. Проте, пов'язану лексику сервіси можуть генерувати непогано. Для отримання адекватного списку потрібно як мінімум працювати з текстами з ТОПу за запитом (і краще ТОП-50, а не ТОП-10). При цьому, зрозуміло, тексти в ТОПі повинні бути досить високої якості. За низькочастотних запитах не завжди вдається набрати достатню базу.
Як правильно готувати LSI-тексти?
Ну ось ми і дісталися до головного.
Якщо ви уважно читали попередню частину, то могли задатися питанням - а чи треба взагалі цим заморочуватися? адже:
- Метод не ідеальний, має безліч обмежень.
- Пошуковики явно використовують куди більш складні алгоритми.
- Для отримання адекватного списку потрібна хороша вибірка даних, яку не завжди просто отримати.
- Самі слова, що задають тематику, важливі в першу чергу для захисту від фільтрів. Саме в ранжируванні допомагають швидше не класичні LSI-слова, а розширення з пошукових запитів.
- Писати тексти з LSI - значить додатково напружувати копірайтера. Інакше кажучи - відволікати його увагу від інших важливих елементів тексту та оплачувати працю за дорожчою ставкою. А ще - підказувати шлях, як можна написати статтю зовні якісно.
- При цьому все одно є ризик отримати водянистий текст з абияк вставленими термінами.
Я вважаю, що мода на LSI (як і у випадку більшості трендів) в значній мірі підігріта штучно. Це в першу чергу спосіб позиціонувати свої послуги з написання текстів як більш якісні або просунути сервіс з пошуку тематичних слів. По крайней мере, у мене склалося саме таке враження після читання англомовних матеріалів.
При цьому зарубіжні SEO-шники не особливо обтяжують себе пошуком доказів. Скріншот типовою статті з порадами по SEO: 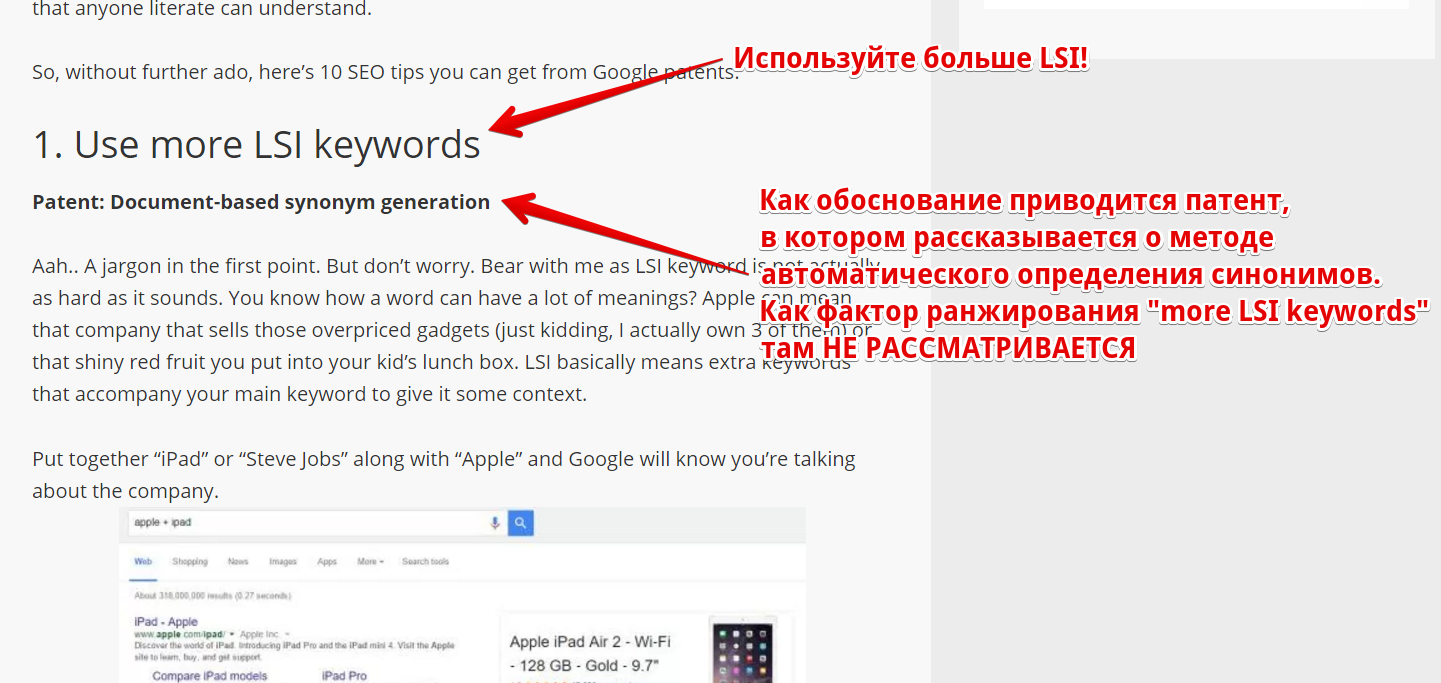
(Привіт всім, хто любить повторювати мантру, що, мовляв, інтернет-маркетинг в Росії відстає на 3 роки. У російськомовних матеріалах я в цілому бачив більш критичне ставлення до теми, а сервіси в Рунеті позиціонують свої послуги куди більш акуратно, не видаючи за чарівну кнопку. Втім, це суб'єктивне спостереження, чисто особисті враження. Можливо, мені попалися не ті статті. На Заході їх дуже багато.)
Однак! Незважаючи на всі мінуси, використовувати LSI можна і потрібно. Потрібно тільки робити це ефективно і враховувати наведений вище перелік проблем.
Мій варіант використання LSI
Схема дуже проста.
1. Отримуємо список тематичних слів для кожної теми, яку плануємо віддати копірайтер. Зберігаємо їх леми. Можна використовувати безкоштовний сервіс Олександра Арсёнкіна: https://arsenkin.ru/tools/sp/ або платні текстові аналізатори (переконайтеся тільки, що вони не обмежуються парсинга подстветок)
2. Однак в ТЗ копірайтеру слова НЕ вказуємо. Головне завдання - отримати від нього адекватний, вирішальний завдання користувача текст. Саме на це і має бути акцент.
3. Отримані на перевірку тексти проганяє через лемматізатор (теж є у Арсёнкіна: https://arsenkin.ru/tools/lemma/ ) І порівнюємо зі списком LSI-лем з першого етапу. Для швидкого порівняння списків можна використовувати, наприклад: https://bez-bubna.com/free/compare.php
4. Якщо значної частини LSI-лем в тексті немає - дивимося його уважніше. Можливо, з якістю тексту щось не в порядку. Якщо все добре і стаття дає нормальний відповідь на запит - вставляємо слова і публікуємо. Якщо ж є проблеми - відправляємо на доопрацювання. Знову вимагаємо зробити добре, а не просто додати термінів.
У чому сіль?
По-перше, ми не збурюємо копірайтера зайвими вимогами.
По-друге, отримуємо напів-автоматичний критерій для відбраковування поганих статей. Нормальний, людський текст буде містити багато LSI без всяких нагадувань. Якщо, звичайно, тематичні слова були зібрані коректно.
По-третє, економимо свій час на розбір LSI. Просто так вивантажити з сервісу слова і віддати на впровадження не вийде. У них все одно буде потрапляти терміни з суміжних тематик (і не тільки: помилок може бути багато). Якщо давати LSI в ТЗ - доведеться чистити все результати. Якщо використовувати по моїй схемі - тільки деякі.
Завершальний етап: підсилюємо текст новими розширеннями
Після публікації тексту потрібно почекати пару місяців, поки накопичиться статистика по переходах на нього, а потім переробити контент, враховуючи реальні запити користувачів.
Вище я цитував доповідь співробітника Яндекса, з якого випливає, що найбільш ефективний шлях отримання додаткових тематичних слів - робота з пошуковими запитами. Саме на основі цієї ідеї реалізований інструмент по додатковій оптимізації сторінок в моєму сервісі https://bez-bubna.com/ (Точніше, його частина).
Загальний принцип дуже простий: дивимося склад пошукових запитів, порівнюємо з текстом на сторінці і знаходимо леми, які відсутні в тексті, але часто зустрічаються в запитах. Чому це працює?
Забудемо про доповідь Яндекса. Припустимо навіть впливу на просування основного ключа (головна функція LSI) слова з запитів не мають. Тоді вони сприяють просуванню по безлічі низькочастотних запитів, які немислимо передбачити на етапі написання. Особлива краса тут в тому, що можна виправити недостатньо ефективне семантичне ядро, швидко розширити семантику сторінки.
Крім того, пошуковий попит нестабільний. З'являються нові запити, під які ще дуже мало контенту в Інтернеті. Використовуючи сервіс, ви маєте шанс зловити ці перспективні ключі з малою конкуренцією і зробити контент більш актуальним.
Ось приклад - скріншот аналізу мого поста про охоплення записи ВК : 
Метод ефективний навіть в самому незграбно виконанні - см. експеримент по автоматичної вставці ключів . На практиці ж потрібно не просто впихати нові розширення, але і додавати контент (або по-новому розставляти акценти), щоб сторінка давала адекватну відповідь на ці нові запити.
Тобто: опрацювання сторінки за допомогою інструменту виходить за рамки простої текстової оптимізації. Це робота відразу в кількох напрямах, даний підвищення якості контенту. Це окупається (див. кейс з розрахунком рентабельності : В ньому не тільки виріс трафік, але і знизився відсоток відмов).
Короткі висновки для тих, хто перегорнув, не читаючи
- LSI - один із сучасних підходів до аналізу текстів. Має ряд обмежень і недоліків, це не єдиний метод, який використовують пошукові системи.
- Аналіз пов'язаної лексики найбільш ефективний у визначенні малоцінних «рідких» текстів і знаходженні документів, які можуть відповідати потребам користувача, хоча і не містять ключових слів, які він ввів. Важливість LSI як такого для ранжирування сторінок з ненульовий текстової релевантностью сумнівна.
- Використовувати списки LSI-слів, які генерують різні сервіси, найкраще на етапі прийому робіт для швидкої оцінки і додаткової оптимізації. У ТЗ же коштувати включати ближчі до реальності критерії якості тексту.
- Завершальний етап роботи зі сторінкою - посилення контенту за допомогою розширення семантики і опрацювання в плані інтересів користувача, які не були прийняті до уваги на початку (вихідна точка - реальна статистика за запитами, які давали трафік на сторінку). На даний момент єдиний публічний інструмент для автоматизації цього етапу є в сервісі https://bez-bubna.com/ .
Ми вже давно щомісяця даємо від 1000 ТЗ за статтями. І з тих пір, як впровадили більш активну роботу з опрацювання підзаголовків + LSI, змінилися дві речі:
1. З появою списку LSI з 20-60 тематичних слів - копірайтера можна додатково заряджати на більш якісний матеріал.
Копірайтеру складніше написати марення, якщо треба обов'язково згадати слова, що підвищують цінність та інформативність статті.
(Одного разу клієнт прийшов з текстом по темі «нежить», в якому не було слова «соплі» - копірайтер все здалося нормальним, а покупець не був спецом по ТЗ).
Часто копірайтери сліпо пишуть в рамках ключів, які їм дають. LSI частково вирішує цю проблему.
2. Більш детальне опрацювання ТЗ в результаті дала якісні результати: середні позиції за статтями, середній показник залучення додаткового трафив по мікроНЧ, середня відвідуваність - все виросло.
У підсумку - навіть якщо окремий параметр LSI має невелику абсолютну величину, то як доп.фактор, який конкуренти не використовують - він може бути істотним і давати хороший результат.
Тим більше, часу займає небагато.
Не бачу причини не юзати.
Що таке LSI насправді?Чому я загострюю на цьому увагу?
Як правильно готувати LSI-тексти?
Якщо ви уважно читали попередню частину, то могли задатися питанням - а чи треба взагалі цим заморочуватися?
У чому сіль?
Чому це працює?