Sieciowe systemy plików i Linux
Sieciowy system plików jest abstrakcją sieciową nad zwykłym systemem plików, umożliwiając klientowi zdalnemu dostęp do niego przez sieć w taki sam sposób, jak podczas uzyskiwania dostępu do lokalnych systemów plików. Chociaż NFS nie jest pierwszym systemem sieciowym, rozwinął się do poziomu najbardziej funkcjonalnego i popularnego sieciowego systemu plików w systemie UNIX®. NFS umożliwia współużytkowanie wspólnego systemu plików dla wielu użytkowników i centralizację danych w celu zminimalizowania miejsca na dysku wymaganego do jego przechowywania.
Ten artykuł rozpoczyna się krótkim przeglądem historii NFS, a następnie przechodzi do badania architektury NFS i dalszego jej rozwijania.
Historia NFS
Pierwszy sieciowy system plików nazywał się FAL (File Access Listener) i został opracowany w 1976 roku przez DEC (Digital Equipment Corporation). Była to implementacja protokołu DAP (Data Access Protocol) i była częścią pakietu protokołów DECnet. Podobnie jak w przypadku TCP / IP, DEC opublikował specyfikacje swoich protokołów sieciowych, w tym DAP.
NFS był pierwszym nowoczesnym systemem plików sieciowych zbudowanym na szczycie IP. Jego prototyp można uznać za eksperymentalny system plików opracowany w Sun Microsystems na początku lat 80-tych. Biorąc pod uwagę popularność tego rozwiązania, protokół NFS został wprowadzony jako specyfikacja RFC, a następnie przekształcił się w NFSv2. NFS szybko stał się standardem dzięki możliwości interakcji z innymi klientami i serwerami.
Następnie standard został uaktualniony do wersji NFSv3 zdefiniowanej w RFC 1813. Ta wersja protokołu była bardziej skalowalna niż poprzednie i obsługiwała większe pliki (ponad 2 GB), nagrywanie asynchroniczne i TCP jako protokół transportowy. NFSv3 określa kierunek rozwoju systemu plików dla sieci globalnych (WAN). W 2000 r., Jako część specyfikacji RFC 3010 (zaktualizowanej w wersji RFC 3530), NFS został przeniesiony do środowiska korporacyjnego. Sun wprowadził bardziej bezpieczny NFSv4 z obsługą stanową (poprzednie wersje NFS nie wspierały zachowania stanu, czyli były bezstanowe). Do tej pory najnowszą wersją NFS jest wersja 4.1, zdefiniowana w RFC 5661, w której równoległy dostęp do serwerów rozproszonych został dodany do protokołu poprzez rozszerzenie pNFS.
Historia NFS, w tym specyficzne RFC opisujące jego wersje, jest pokazana na rysunku 1.
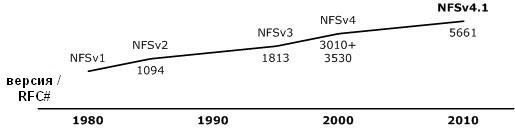
Rysunek 1. Historia NFS
Co zaskakujące, NFS jest rozwijany od prawie 30 lat. Jest to wyjątkowo stabilny i przenośny sieciowy system plików z wyjątkową skalowalnością, wydajnością i jakością usług. Wraz ze wzrostem prędkości i zmniejszeniem opóźnień w wymianie danych w sieci, NFS pozostaje popularnym sposobem implementacji systemu plików w sieci. Nawet w przypadku sieci LAN wirtualizacja prosi o przechowywanie danych w sieci, aby zapewnić dodatkową mobilność maszynom wirtualnym. NFS obsługuje także najnowsze modele środowiska komputerowego, których celem jest optymalizacja infrastruktur wirtualnych.
Architektura NFS
NFS używa standardowego modelu architektury klient-serwer (jak pokazano na rysunku 2). Serwer jest odpowiedzialny za wdrożenie systemu udostępniania plików i pamięci masowej, z którą łączą się klienci. Klient implementuje interfejs użytkownika do współużytkowanego systemu plików zamontowanego wewnątrz lokalnego obszaru plików klienta.
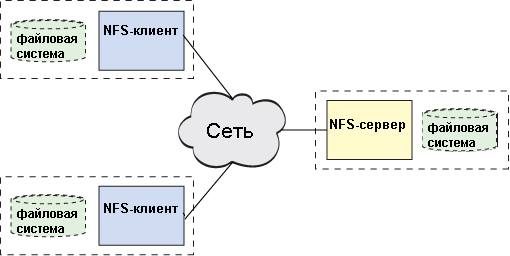
Rysunek 2. Implementacja modelu klient-serwer w architekturze NFS
W systemie Linux® przełącznik wirtualnego systemu plików (VFS) umożliwia jednoczesną obsługę wielu systemów plików na jednym hoście (na przykład system plików ISO 9660 na dysku CD-ROM i system plików ext3fs na lokalnym dysku twardym). Przełącznik wirtualny określa, który dysk jest wysyłany, a co za tym idzie, który system plików powinien być używany do przetwarzania żądania. Dlatego NFS ma taką samą kompatybilność jak inne systemy plików używane w Linuksie. Jedyna różnica w porównaniu z NFS polega na tym, że żądania I / O zamiast lokalnego przetwarzania na hoście mogą być wysyłane do sieci.
VFS określa, że odebrane żądanie jest związane z NFS i przekazuje je do procedury obsługi NFS znajdującej się w jądrze. Procedura obsługi NFS przetwarza żądanie we / wy i tłumaczy je na procedurę NFS (OPEN, ACCESS, CREATE, READ, CLOSE, REMOVE itd.). Procedury te, opisane w oddzielnej specyfikacji RFC, definiują zachowanie protokołu NFS. Wymagana procedura jest wybierana w zależności od żądania i jest wykonywana przy użyciu technologii RPC (zdalne wywołanie procedury). Jak sama nazwa wskazuje, RPC umożliwia wykonywanie wywołań procedur między różnymi systemami. Usługa RPC łączy żądanie NFS z jego argumentami i wysyła wynik do odpowiedniego zdalnego hosta, a następnie monitoruje odbiór i przetwarzanie odpowiedzi w celu zwrócenia jej do inicjatora żądania.
RPC zawiera również ważny poziom XDR (zewnętrzna reprezentacja danych), dzięki czemu wszyscy użytkownicy NFS dla tych samych typów danych korzystają z tego samego formatu. Gdy platforma wysyła żądanie, typ danych, z których korzysta, może się różnić od typu danych używanych na hoście przetwarzającym żądanie. XDR zajmuje się konwersją typów do standardowej reprezentacji (XDR), więc platformy używające różnych architektur mogą współdziałać i współdzielić systemy plików. XDR definiuje format bitowy dla typów takich jak float i kolejność bajtów dla typów takich jak tablice o stałej i zmiennej długości. Chociaż XDR jest znany głównie ze swojego wykorzystania w NFS, ta specyfikacja może być przydatna we wszystkich przypadkach, gdy musisz pracować w tym samym środowisku z różnymi architekturami.
Po przetłumaczeniu danych do standardowego widoku XDR żądanie jest przesyłane przez sieć przy użyciu określonego protokołu transportowego. Wcześniejsze implementacje NFS korzystały z protokołu UDP, ale obecnie TCP jest używany do zapewnienia większej niezawodności.
Po stronie serwera NFS używany jest podobny algorytm. Żądanie jest generowane przez stos sieciowy przez poziom RPC / XDR (w celu konwersji typów danych zgodnie z architekturą serwera) i przechodzi do serwera NFS, który jest odpowiedzialny za przetwarzanie żądania. Tam żądanie jest wysyłane do demona NFS w celu określenia docelowego systemu plików, do którego jest adresowane, a następnie wraca do VFS, aby uzyskać dostęp do tego systemu plików na dysku lokalnym. Pełny schemat tego procesu pokazano na rysunku 3. Lokalny system plików serwera jest standardowym systemem plików Linux, na przykład ext4fs. W istocie NFS nie jest systemem plików w tradycyjnym znaczeniu tego słowa, lecz protokołem zdalnego dostępu do systemów plików.
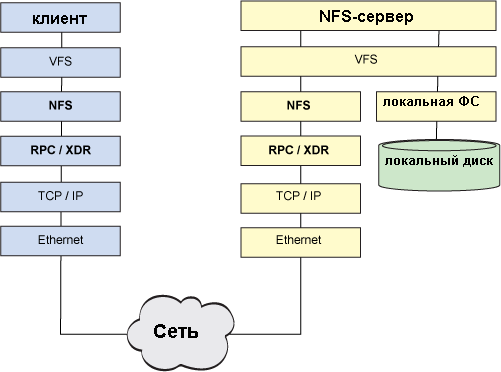
Rysunek 3. Interakcja między klientem NFS a serwerem NFS
W przypadku sieci o długim opóźnieniu NFSv4 oferuje specjalną procedurę złożoną (procedura złożona). Ta procedura pozwala umieścić wiele wywołań RPC w ramach jednego żądania, aby zminimalizować koszt wysyłania żądań przez sieć. Również w tej procedurze zaimplementowano funkcję oddzwaniania, aby otrzymywać odpowiedzi.
Na początek
Nfs roto
Gdy klient rozpoczyna pracę z NFS, pierwszym krokiem jest wykonanie operacji montowania, polegającej na zamontowaniu zdalnego systemu plików w lokalnym obszarze systemu plików. Proces ten rozpoczyna się od wywołania procedury montowania (jednej z funkcji systemu Linux), która jest przekierowywana przez VFS do komponentu NFS. Następnie, używając wywołania RPC funkcji get_port na zdalnym serwerze, określa się numer portu, który ma być użyty do zamontowania, a klient wysyła żądanie zamontowania przez RPC. To żądanie po stronie serwera jest przetwarzane przez specjalnego demona rpc.mountd odpowiedzialnego za protokół montowania (protokół montowania). Demon sprawdza, czy system plików żądany przez klienta znajduje się na liście systemów dostępnych na tym serwerze. Jeśli żądany system istnieje, a klient ma do niego dostęp, uchwyt systemu montowania jest określony w odpowiedzi RPC montowania. Klient przechowuje informacje o lokalnych i zdalnych punktach montowania i może wykonywać żądania we / wy. Protokół montowania nie jest bezpieczny z punktu widzenia bezpieczeństwa, więc NFSv4 używa wewnętrznych wywołań RPC zamiast niego, które mogą również kontrolować punkty montowania.
Aby odczytać plik, musisz go najpierw otworzyć. W RPC nie ma procedury OPEN, zamiast tego klient po prostu sprawdza, czy określony plik i katalog istnieje w zamontowanym systemie plików. Klient uruchamia się, wykonując żądanie RPC GETATTR do katalogu, w odpowiedzi na które atrybuty katalogu są zwracane lub wskaźnik, że katalog nie istnieje. Następnie, aby sprawdzić obecność pliku, klient wykonuje żądanie LPCUP RPC. Jeśli plik istnieje, zostanie wysłane żądanie RPC GETATTR, aby znaleźć atrybuty pliku. Korzystając z informacji uzyskanych w wyniku udanych wywołań LOOKUP i GETATTR, klient tworzy deskryptor pliku, który jest dostarczany użytkownikowi do przyszłych żądań.
Po zidentyfikowaniu pliku w zdalnym systemie plików klient może wykonywać żądania RPC typu READ. To żądanie składa się z deskryptora pliku, stanu, przesunięcia i liczby bajtów do odczytania. Klient używa stanu do określenia, czy operacja może być wykonana w danym momencie, tj. Czy plik jest zablokowany? Przesunięcie wskazuje pozycję, od której należy rozpocząć odczyt, a liczba bajtów (liczba) określa, ile bajtów ma zostać odczytanych. W rezultacie wywołanie RPC do serwera READ nie zawsze zwraca tyle bajtów, ile jest wymagane, ale wraz ze zwróconymi danymi zawsze wysyła ile bajtów zostało wysłanych do klienta.
I innowacje w NFS
Najciekawsze są dwie najnowsze wersje NFS - 4 i 4.1, na przykładzie których można zbadać najważniejsze aspekty ewolucji technologii NFS.
Przed nadejściem NFSv4 do wykonywania zadań związanych z zarządzaniem plikami, takich jak mount, lock itp. istniały specjalne dodatkowe protokoły. W NFSv4 proces zarządzania plikami został uproszczony do jednego protokołu; dodatkowo, ponieważ ta wersja UDP nie jest już używana jako protokół transportowy. NFSv4 zawiera obsługę semantyki dostępu do plików UNIX i Windows®, która umożliwia NFS integrację z innymi systemami operacyjnymi w „naturalny” sposób.
W NFSv4.1 wprowadzono koncepcję równoległego NFS (równoległego NFS - pNFS) w celu zwiększenia skalowalności i wydajności. Aby zapewnić wyższy poziom skalowalności, NFSv4.1 implementuje architekturę, w której dane i metadane (znaczniki) są dystrybuowane między urządzeniami w taki sam sposób, jak w systemach plików klastra. Jak pokazano na rysunek 4 , pNFS dzieli ekosystem na trzy komponenty: klient, serwer i pamięć. W tym przypadku pojawiają się dwa kanały: jeden do transmisji danych, a drugi do transmisji poleceń sterujących. pNFS oddziela dane od opisujących je metadanych, zapewniając architekturę dwukanałową. Gdy klient chce uzyskać dostęp do pliku, serwer wysyła go metadanymi z „znacznikiem”. Metadane zawierają informacje o lokalizacji pliku na urządzeniach pamięci masowej. Po otrzymaniu tych informacji klient może uzyskać bezpośredni dostęp do repozytorium bez konieczności interakcji z serwerem, co przyczynia się do zwiększenia skalowalności i wydajności. Gdy klient zakończy pracę z plikiem, potwierdza zmiany wprowadzone w pliku i jego „znaczniku”. W razie potrzeby serwer może zażądać metadanych klienta ze znacznikami.
Wraz z pojawieniem się pNFS dodano kilka nowych operacji do protokołu NFS w celu obsługi tego mechanizmu. Metoda LayoutGet służy do pobierania metadanych z serwera, metoda LayoutReturn „uwalnia” metadane przechwycone przez klienta, a metoda LayoutCommit ładuje znaczniki otrzymane od klienta do repozytorium, dzięki czemu staje się dostępne dla innych użytkowników. Serwer może odwołać metadane od klienta za pomocą metody LayoutRecall. Metadane znaczników są dystrybuowane na wielu urządzeniach pamięci masowej, aby zapewnić równoczesny dostęp i wysoką wydajność.
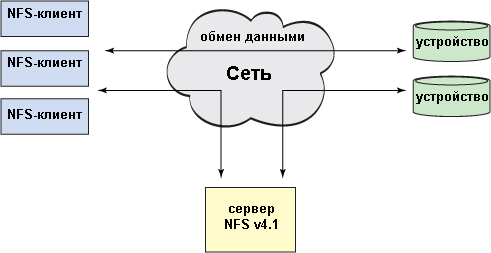
Rysunek 4. Architektura pNFS w wersji 4.1 NFS
Dane i metadane są przechowywane na urządzeniach pamięci masowej. Klienci mogą wykonywać bezpośrednie żądania we / wy na podstawie wynikowego znacznika, podczas gdy serwer NFSv4.1 przechowuje i zarządza metadanymi. Ta funkcjonalność sama w sobie nie jest nowa, ale do pNFS dodano obsługę różnych metod dostępu do pamięci. Dzisiaj pNFS obsługuje protokoły blokowe (Fibre Channel), protokoły obiektowe i sam NFS (nawet w postaci pNFS).
Rozwój NFS trwa, a we wrześniu 2010 r. Opublikowano wymagania dotyczące NFSv4.2. Niektóre z innowacji wiążą się z obserwowaną migracją technologii przechowywania danych w kierunku wirtualizacji. Na przykład w środowiskach wirtualnych z hiperwizorem, duplikacja danych jest bardzo prawdopodobna (kilka systemów operacyjnych odczytuje / zapisuje i buforuje te same dane). W związku z tym pożądane jest, aby system pamięci masowej jako całość rozumiał, gdzie występuje duplikacja. Takie podejście pozwala zaoszczędzić miejsce w pamięci podręcznej klienta i całkowitą pojemność pamięci. W NFSv4.2 proponuje się użycie „mapy blokowej współdzielonych bloków” w celu rozwiązania tego problemu. Ponieważ nowoczesne systemy pamięci masowej są coraz częściej wyposażone we własną wewnętrzną moc obliczeniową, kopiowanie jest wprowadzane po stronie serwera, co pozwala zmniejszyć obciążenie podczas kopiowania danych w sieci wewnętrznej, gdy można to skutecznie wykonać na samym urządzeniu pamięci masowej. Inne innowacje obejmują buforowanie fragmentów plików pamięci flash i zalecenia dotyczące dostosowywania I / O po stronie klienta (na przykład przy użyciu mapadvise).
Alternatywy NFS
Chociaż NFS jest najpopularniejszym sieciowym systemem plików w systemach UNIX i Linux, oprócz niego istnieją inne sieciowe systemy plików. Na platformie Windows® najczęściej używany jest SMB, znany również jako CIFS; podczas gdy Windows obsługuje również NFS, a także Linux obsługuje SMB.
Jeden z najnowszych rozproszonych systemów plików obsługiwanych przez Linuxa, Ceph, został pierwotnie zaprojektowany jako odporny na błędy system plików zgodny z POSIX. Aby uzyskać więcej informacji o Cephie, zobacz Zasoby .
Warto również wspomnieć o systemach plików OpenAFS (wersja open source rozproszonego systemu plików Andrew opracowana w Carnegie Mellon University i IBM), GlusterFS (rozproszony system plików ogólnego przeznaczenia do organizowania skalowalnych magazynów danych) i Luster (sieciowy system plików z ogromną równoległością dla rozwiązania klastrowe). Wszystkie te systemy open source mogą być używane do tworzenia rozproszonych repozytoriów.
H wniosek
Kontynuowana jest ewolucja systemu plików NFS. Podobnie jak Linux, odpowiedni do obsługi tanich, wbudowanych i wysokowydajnych rozwiązań, NFS zapewnia architekturę skalowalnych rozwiązań pamięci masowej odpowiednich zarówno dla indywidualnych użytkowników, jak i organizacji. Jeśli spojrzysz na ścieżkę już przyjętą przez NFS i perspektywy jej dalszego rozwoju, staje się jasne, że ten system plików będzie nadal zmieniał nasze poglądy na temat sposobu wdrażania i używania technologii przechowywania plików.
Zasób
- Sieciowe systemy plików i Linux (http://www.ibm.com/developerworks/linux/library/l-network-filesystems/index.html?S_TACT=105AGX99&S_CMP=CP) : oryginalny artykuł (en).
- NFS to standard specyfikacji przenośnego i wieloplatformowego sieciowego systemu plików. NFS jest udokumentowany w kilku specyfikacjach, w tym w pierwszej implementacji NFSv2 , Nfsv3 , Nfsv4 najnowsza wersja NFSv4.1 . Kierunek dalszego rozwoju NFS można znaleźć w Wymagania NFS v4.2 .
- Yet Another NFS (YANFS) - Projekt Sun, wcześniej nazywany Webnfs . System plików YANFS jest implementacją Java ™ NFSv3 i RPC / XDR do uzyskiwania dostępu do NFS z aplikacji Java.
- XDR Jest standardem kodowania danych, który umożliwia hostom o różnych architekturach komunikację przez sieć przy użyciu standardowych typów danych.
- Linux obsługuje różne systemy plików dla różnych urządzeń pamięci masowej. Ta możliwość jest zapewniona dzięki integracji różnych systemów plików, sterowników pamięci masowej i VFS. Więcej informacji na temat VFS można znaleźć w artykule „ Anatomia systemu plików Linux „(developerWorks, październik 2007).
- Oprócz NFS istnieją inne sposoby budowania pamięci plików sieciowych. Możesz także użyć systemów plików. OpenAFS , GlusterFS , Połysk i Ceph . Więcej informacji na temat Ceph można znaleźć w artykule. Ceph: rozproszony system plików petabajtów w Linuksie „(developerWorks, maj 2010).
Html?